Презентация "Организация и управление большими объектами" по информатике – проект, доклад
 Слайд 1
Слайд 1 Слайд 2
Слайд 2 Слайд 3
Слайд 3 Слайд 4
Слайд 4 Слайд 5
Слайд 5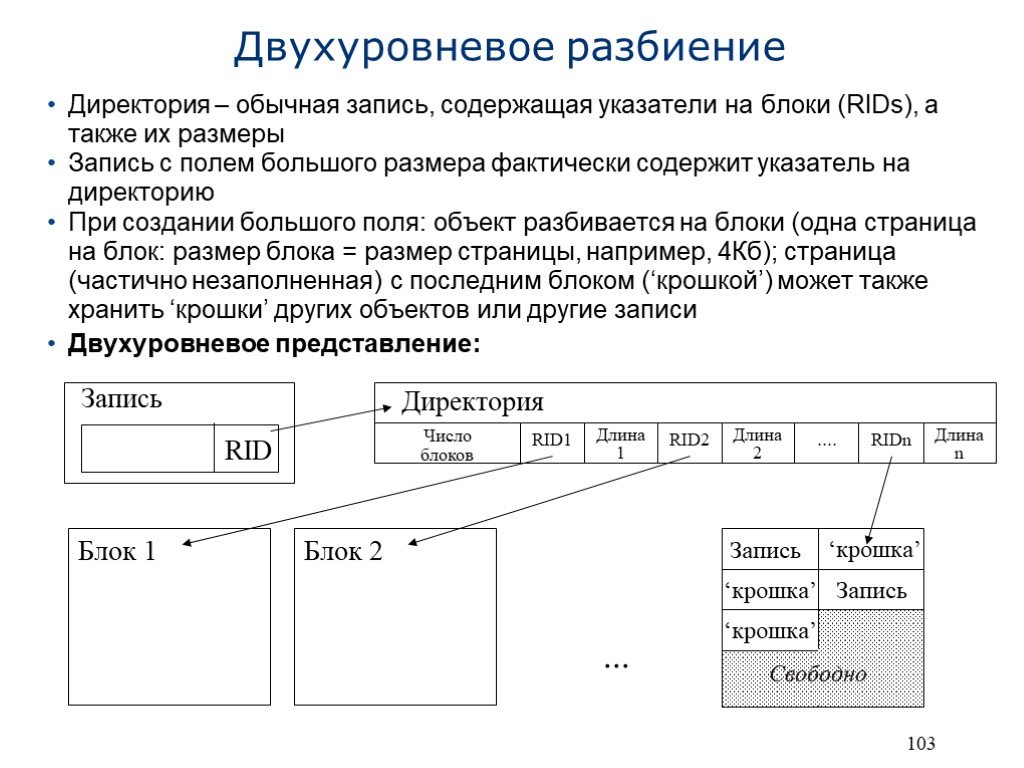 Слайд 6
Слайд 6 Слайд 7
Слайд 7 Слайд 8
Слайд 8 Слайд 9
Слайд 9 Слайд 10
Слайд 10 Слайд 11
Слайд 11 Слайд 12
Слайд 12 Слайд 13
Слайд 13 Слайд 14
Слайд 14 Слайд 15
Слайд 15 Слайд 16
Слайд 16 Слайд 17
Слайд 17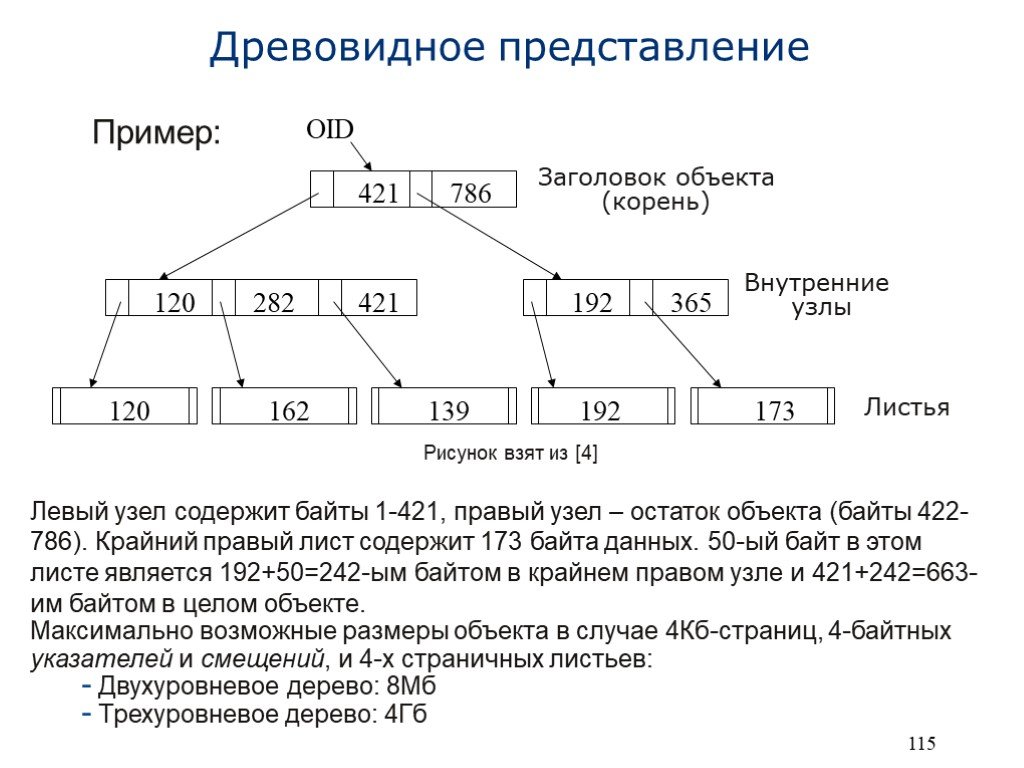 Слайд 18
Слайд 18 Слайд 19
Слайд 19 Слайд 20
Слайд 20 Слайд 21
Слайд 21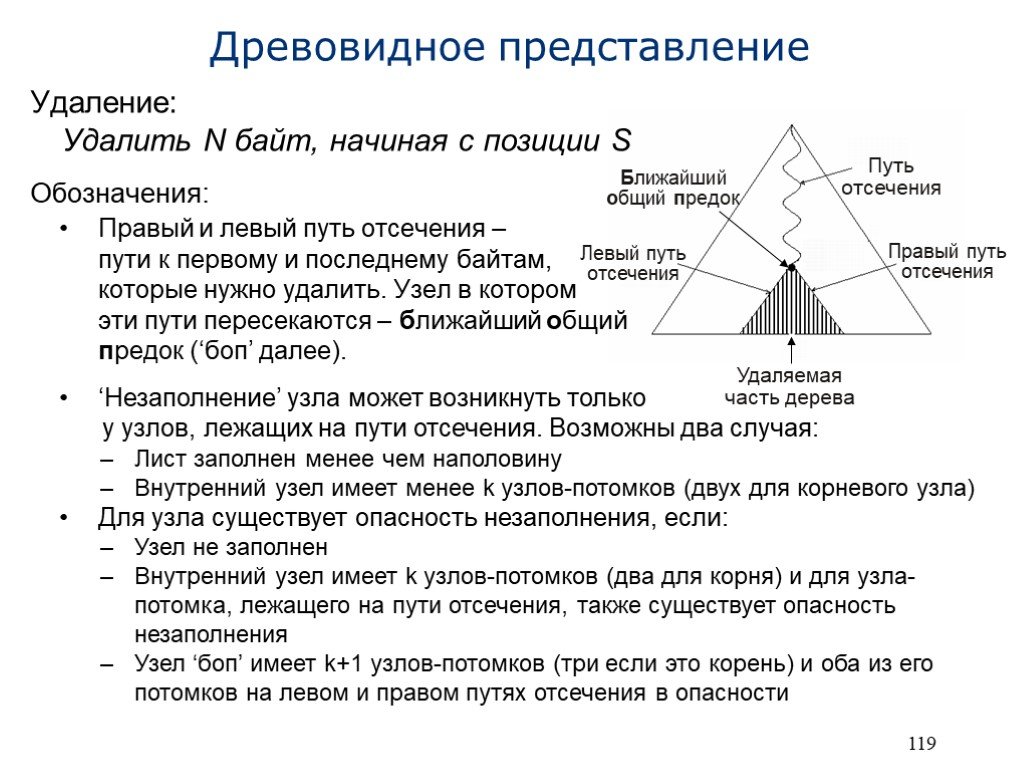 Слайд 22
Слайд 22 Слайд 23
Слайд 23 Слайд 24
Слайд 24 Слайд 25
Слайд 25 Слайд 26
Слайд 26Презентацию на тему "Организация и управление большими объектами" можно скачать абсолютно бесплатно на нашем сайте. Предмет проекта: Информатика. Красочные слайды и иллюстрации помогут вам заинтересовать своих одноклассников или аудиторию. Для просмотра содержимого воспользуйтесь плеером, или если вы хотите скачать доклад - нажмите на соответствующий текст под плеером. Презентация содержит 26 слайд(ов).
Слайды презентации
Список похожих презентаций

Организация системы прерывания
Возможным решением здесь может быть, например, периодическая остановка текущей программы и выполнение других программ, производящих опрос устройств ...
Группы безопасности управление пользователями
Учетная запись. Для управления пользователями в MS Windows используется понятие учетной записи. Учетная запись в Active Directory — объект, содержащий ...
Организация сбора макулатуры в районе Северное Измайлово
Уровень сбора макулатуры. Результаты социологического опроса. . . . . Акция «Сохраним дерево» 21 октября и 7 ноября 2011 года в ГБОУ СОШ № 619. Пункты ...
Работа с объектами в редакторе Blender
Работа с объектами. Ctrl+J – объеденяет объекты в один объект Ctrl+P – создает зависимость родитель потомок (Последний выбранный объект становится ...
Работа с объектами текстового документа
Цели урока:. Рассмотреть, в каком порядке чаще всего создается текстовый документ. Дать определения процессов создания, редактирования и форматирования ...
Отношения между объектами
Все объекты находятся в определённых отношениях между собой. Больше Меньше. Отношения имеют имена: меньше, больше, дороже, уже, шире, выше, ниже. ...
Программное управление компьютером
КОМПЬЮТЕР (computer)- автоматическое устройство или система, способная выполнять заданную, четко определенную последовательность операций, таких как, ...
Организация и основные характеристики памяти компьютера
Компьютер – это универсальное (многофункциональное) автоматическое программно управляемое электронное устройство, предназначенное для хранения, обработки ...
Организация и структура телекоммуникационных компьютерных сетей
Телекоммуникация – это обмен информацией на расстоянии с помощью средств связи. Почта, телефон, телеграф обеспечивают человеку связь, возможность ...
Организация ввода-вывода в С++
Все средства ввода-вывода в языке C++ реализованы в виде библиотечных перегруженных операций > (извлечения и вставки), манипуляторов, классов потоков, ...
Организация и основные устройства память компьютера
Виды памяти компьютера. Оперативная Постоянная Внешняя. Оперативная память предназначена для хранения переменной информации, допускает изменение своего ...
Организация АРМ инженера Help Desk ИТ - специалиста технической поддержки
Библиотека передового опыта в области организации деятельности ИТ служб – ITIL. Базовые определения: Пользователь – любой пользователь программно-технического ...
Институциональные репозитории: создание и управление
Открытый доступ к результатам научных исследований. Будапештская инициатива «Открытый доступ» (Budapest Open Access Initiative). Берлинская декларация ...
Защита файлов и управление доступом к ним
Компьютерная безопасность. информационная безопасность, безопасность самого компьютера, организация безопасной работы человека с компьютерной техникой. ...
Организация управления информационными технологиями
ИСУ. Организация управления инфраструктурою. Поскольку технологии и подходы постоянно меняются, для правильной организации управления информационными ...
Организация компьютерной безопасности и защита информации
Безопасность информационной системы. Безопасность информационной системы - это свойство, заключающее в способности системы обеспечить ее нормальное ...
Отношения между объектами
Отношения – это связь между объектами. Вершина слева ниже. Примеры отношений:. Дешевле (дороже) Длиннее (короче) Добрее (злее). Родственные отношения. ...
Организация локальных сетей
Цель урока:. Познакомить с понятием «локальная сеть», топология сети. Дать представление об аппаратном обеспечение сети. План:. Локальные компьютерные ...
Отношения между объектами
вспомнить.Все объекты реального мира связаны друг с другом разными отношениями Отношения бывают разные: пространственные, временные, порядковые, ...

Организация проектной деятельности на уроках информатики как способ формирования ключевых компетенций школьников
Проект. Проектное обучение мы рассматриваем как развивающее, базирующееся на последовательном выполнении комплексных учебных проектов с информационными ...Конспекты
Файлы и папки Размер файла. Работа с объектами файловой системы
Учитель: Шпак Наталия Петровна. Класс:. 6. Тема урока. :. Файлы и папки Размер файла. Работа с объектами файловой системы. . . Цели урока:. ...Файлы, папки и ярлыки. Работа с объектами ОС Windows
Тема урока: Файлы, папки и ярлыки. Работа с объектами ОС Windows. Цель урока:. . - познакомить учащихся с определениями и характеристиками основных ...Отношения между объектами
Технологическая карта урока. Матвеева. Информатика . 4 класс. ФГОС. Урок 4. Отношения между объектами. Цели урока:. - развитие любознательности ...Работа с объектами в векторных графических редакторах
Конспект урока в 9 классе на тему. “ Работа с объектами в векторных графических редакторах”. Выполнила: учитель информатики и ИКТ. ...Организация табличных баз данных. Сортировка. Фильтрация
Урок № 9. Дата: 30.10.13 г. Класс: 11. Предмет:. Информатика. Тема урока:. Организация табличных баз данных. Сортировка. Фильтрация. Цели:. ...Организация локальных и глобальных сетей
Дистанционное образование-образование, реализуемое посредством дистанционного обучения. Преимущества дистанционного обучения. В процессе дистанционного ...Операции с объектами Windows
Открытый урок. . по информатике в 5 классе. «Операции с объектами. Windows. ». Провел учитель информатики:. Фудымосвкий Ю.И. ...Операции над несколькими объектами с помощью панели Свойств в CorelDraw
Метелева Светлана Александровна. Учитель информатики и ИКТ. 1 квалификационная категория. МОАУ СОШ №10 г. Кирова. Кировская область. контактный ...Действия над объектами
Дата:. 8.04.14. Предмет:. информатика. Класс. 4А. Тема:. Действия над объектами. Тип урока. : изучение новых знаний. Цели урока:. Обучающая: ...Советы как сделать хороший доклад презентации или проекта
- Постарайтесь вовлечь аудиторию в рассказ, настройте взаимодействие с аудиторией с помощью наводящих вопросов, игровой части, не бойтесь пошутить и искренне улыбнуться (где это уместно).
- Старайтесь объяснять слайд своими словами, добавлять дополнительные интересные факты, не нужно просто читать информацию со слайдов, ее аудитория может прочитать и сама.
- Не нужно перегружать слайды Вашего проекта текстовыми блоками, больше иллюстраций и минимум текста позволят лучше донести информацию и привлечь внимание. На слайде должна быть только ключевая информация, остальное лучше рассказать слушателям устно.
- Текст должен быть хорошо читаемым, иначе аудитория не сможет увидеть подаваемую информацию, будет сильно отвлекаться от рассказа, пытаясь хоть что-то разобрать, или вовсе утратит весь интерес. Для этого нужно правильно подобрать шрифт, учитывая, где и как будет происходить трансляция презентации, а также правильно подобрать сочетание фона и текста.
- Важно провести репетицию Вашего доклада, продумать, как Вы поздороваетесь с аудиторией, что скажете первым, как закончите презентацию. Все приходит с опытом.
- Правильно подберите наряд, т.к. одежда докладчика также играет большую роль в восприятии его выступления.
- Старайтесь говорить уверенно, плавно и связно.
- Старайтесь получить удовольствие от выступления, тогда Вы сможете быть более непринужденным и будете меньше волноваться.
Информация о презентации
Дата добавления:5 мая 2019
Категория:Информатика
Содержит:26 слайд(ов)
Поделись с друзьями:
Скачать презентацию









