Слайд 1Технология модели «клиент-сервер»
Слайд 2Системные модели
Системная модель определяет: Архитектуру информационной системы Роли и функции компонентов системы Правила взаимодействия компонентов Состав оборудования Состав программных средств, необходимых для функционирования системы
Слайд 3Программные средства
Программы общего назначения (например, операционные системы) Системы управления базами данных Специализированные пакеты программ Уникальные программные компоненты (созданные для этой информационной системы)
Слайд 4Роли программных компонентов
Клиент: реализует взаимодействие с человеком Функциональный модуль: реализует основные функции системы Сервер данных: обеспечивает хранение и доступ к хранимой информации Преобразователь данных Другие
Слайд 5Классы архитектур информационных систем
Однокомпонентные Клиент-сервер Многослойные архитектуры (обычно 3) Гибридные архитектуры
Слайд 6Роли
Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса Компьютер, желающий воспользоваться ресурсов – клиентом. Программы – аналогично Можно для одного ресурса выполнять роль клиента, для другого - сервера
Слайд 74 группы функций приложения:
функции ввода и отображения данных прикладные функции фундаментальные функции хранения и управления информационными ресурсами служебные функции, играющие роль связок между функциями первых трех групп.
Слайд 8
Слайд 9Логические компоненты приложения:
компонент представления, реализующий функции первой группы; прикладной компонент, поддерживающий функции второй группы; компонент доступа к информационным ресурсам,
Слайд 10Различия в реализациях технологии «клиент-сервер»
В какие виды программного обеспечения интегрированы каждый из компонентов Какие механизмы программного обеспечения используются для реализации функций всех трех групп. Как логические компоненты распределяются между компьютерами в сети. Какие механизмы используются для связи компонентов между собой.
Слайд 11Однокомпонентные системы
Все роли программных компонентов реализуются в одной компоненте Специализированный код встроен в базу данных (или наоборот) Как правило, однопользовательские Многие роли необязательны Могут работать автономно
Слайд 12Архитектура клиент-сервер
Роли клиента и сервера данных выполняются, вообще говоря, на разных системах Толстые и тонкие клиенты Особенности: Постоянное соединение на время сеанса Совместное использование данных Высоконадежные системы для ограниченного количества пользователей
Слайд 13Выделяются четыре подхода, реализованные в моделях:
модель файлового сервера (File Server – FS); модель доступа к удаленным данным (Remote Access Data – RDA); модель сервера базы данных (DataBase Server – DBS); модель сервера приложений (Application Server – AS).
Слайд 14Файловый сервер (FS)
Слайд 15Файл-серверная архитектура
Файловый сервер - хранит файлы, предоставляя к ним доступ пользователям сети. Поэтому информационного хранилище естественно расположить на файловом сервере. Все программное обеспечение ИС будет располагаться на сетевых компьютерах. Данная архитектура широко применяется для создания информационных систем с относительно не большим количеством одновременно работающих пользователей (несколько десятков). Для выполнения операций с данными необходимо получить копию этих данных на сетевой компьютер.
Слайд 16Высокий трафик (передача множества файлов, необходимых приложению) Узкий спектр операций манипуляции с данными («данные – это файлы») Отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д.
Слайд 17Модель доступа к удаленным ресурсам (RDA)
Слайд 18унификация интерфейса «клиент-сервер» в виде языка SQL перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД администрирование приложений практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные).
Слайд 19Модель сервера базы данных (DBS)
Слайд 20Модель сервера базы данных (DBS)- особенности
Основа - механизм хранимых процедур. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL–сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД.
Слайд 21Модель сервера базы данных (DBS)- достоинства
Возможность централизованного администрирования прикладных функций Снижение трафика (вместо SQL–запросов по сети направляются вызовы хранимых процедур) Возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры.
Слайд 22Модель сервера базы данных (DBS) - недостатки
Ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональными возможностями с языками третьего поколения. Сфера их использования ограничена конкретной СУБД, не во всех СУБД отсутствует возможность отладки и тестирования хранимых процедур.
Слайд 23RDA + DBS
Поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBS-модель), Более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте
Слайд 24Модель сервера приложений
Слайд 25Трехуровневые ИС
Количество уровней (слоев) программного обеспечения может быть больше двух. (WEB-браузер WEB-сервер сервер баз данных. Поскольку с самого сервера баз данных можно обращаться с запросами к другим серверам, то теоретически может быть построена система, имеющая более чем три уровня. Возможно выделение специфических функций приложения на отдельный сервер сервер приложений. Такая модель называется также AS-модель (AS – Application Server).
Слайд 26Достоинства многоуровневых архитектур
Существует большое количество компонентов Массовое использование в относительно простых системах Средства генерации кода
Слайд 27Недостатки многослойных систем
Неэффективное использование серверов данных Слишком большое количество сетевых обменов Искусственное привязывание ролей к слоям
Слайд 28Многослойные архитектуры
Обычно различают 3 слоя Клиент <-> > представление Средний слой <-> функциональность Сервер данных <-> хранение
Слайд 29«Толстые» и «тонкие» клиенты
«Тонкий» клиент - только запуска сетевого приложения через web-интерфейс. «Толстый» клиент - совмещает компонент представления данных (графический пользовательский интерфейс ОС) и прикладной компонент (вычислительные мощности клиентского компьютера).
Слайд 30Прикладной компонент выделен как важнейший изолированный элемент приложения Для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами.
Слайд 31Активный сервер
Данные должны быть взаимно непротиворечивы. База данных должна отражать некоторые правила предметной области, по которым она функционирует. Необходим постоянный контроль за состоянием базы данных, отслеживание всех изменений и адекватная реакция на них. Необходимо, чтобы возникновение некой ситуации в базе данных четко и оперативно влияло на ход выполнения прикладной программы.
Слайд 32Активный сервер включает в себя:
процедуры базы данных; правила (триггеры); события в базе данных; типы данных, определяемые пользователем.
Слайд 33Процедуры базы данных
Общие части (часто используемые) прикладных программ оформляются в отдельные процедуры, которые хранятся непосредственно в базе данных. Одна процедура может использоваться несколькими прикладными программами. Сокращаются затраты на написание прикладных программ – они составляются из готовых процедур. Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры.
Слайд 34Правила (триггеры)
Механизм правил (триггеров) позволяет программировать обработку ситуаций, возникающих при любых изменениях в базе данных. Правило придается таблице базы данных и применяется при выполнении над ней операций включения, удаления или обновления строк, а также при изменении значений в столбцах таблицы. Применение правила заключается в проверке сформулированных в нем условий, при выполнении которых происходит вызов специфицированной внутри правила процедуры базы данных. Правила также хранятся вместе с базой данных независимо от прикладных программ.

Слайд 35События в базе данных
Механизм событий в базе данных позволяет прикладным программам и серверу базы данных уведомлять другие программы о наступлении в базе данных определенного события и тем самым синхронизировать их работу. Различные прикладные программы и процедуры вызывают события в базе данных, а сервер оповещает монитор прикладных программ об их наступлении. Реакция монитора на события заключается в выполнении действий, которые предусматривает его разработчик.

Слайд 36В базе данных для каждого события создается флажок, состояние которого будет оповещать прикладные программы о том, что некоторое событие имело место. Во все прикладные программы, на ход выполнения которых может повлиять это событие, включается оператор, который оповещает сервер базы данных, что данная программа заинтересована в получении сообщения о наступлении события. Прикладная программа может вызвать событие соответствующим оператором. Как только событие произойдет, каждая зарегистрированная программа может получить сообщение о наступлении события, для чего должна запросить очередное сообщение из очереди событий.
Слайд 37Типы данных, определяемые пользователями
Описание нового типа данных хранится в базе данных и его обработка происходит так же, как и обработка стандартных типов данных.
Слайд 38Распределенные ИС
Процессы децентрализации и информационной интеграции. Адекватное развитие глобальной сетевой инфраструктуры Применении реальных технологий создания распределенных информационных систем.
Слайд 39
Слайд 40Ставится задача - построить информационную систему "клиент-сервер" на базе локальной сети с централизованной базой данных. Выбирается СУБД и средства для разработки приложений. Создается система, представляющая собой комбинацию базы данных и обращающихся к ней приложений, в которых и реализована вся прикладная логика. Увеличение масштаба требует децентрализации хранения и обработки данных и, соответственно, развития информационной системы.
Слайд 41РБД состоит из набора узлов, связанных коммуникационной сетью, в которой: каждый узел — это полноценная СУБД сама по себе; что пользователь любого узла может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле. Для пользователя распределённая система должна выглядеть так же, как нераспределённая система.
Слайд 42Distributed DataBase - DDB
Под распределенной обычно подразумевают базу данных, включающую фрагменты из нескольких баз данных, которые располагаются на различных узлах сети компьютеров, и, возможно управляются различными СУБД. Распределенная база данных выглядит с точки зрения пользователей и прикладных программ как обычная локальная база данных. В этом смысле слово "распределенная" отражает способ организации базы данных, но не внешнюю ее характеристику. ("распределенность" базы данных невидима извне).
Слайд 43Типы распределенных архитектур
Системы недублирующего разбиения (при большом объеме часто меняющихся данных) Системы частичного дублирования (при небольшом объеме часто меняющихся данных) Системы полного дублирования (при небольшом объеме редко меняющихся данных)
. Локальная автономия (local autonomy) Независимость узлов (no reliance on central site) Непрерывные операции (continuous operation) Прозрачность расположения (location independence) Распределенные ограничения целостности Прозрачная фрагментация (frag")
Слайд 44Определение Дэйта распределенных баз данных (DDB)
Локальная автономия (local autonomy) Независимость узлов (no reliance on central site) Непрерывные операции (continuous operation) Прозрачность расположения (location independence) Распределенные ограничения целостности Прозрачная фрагментация (fragmentation independence) Прозрачное тиражирование (replication independence) Обработка распределенных запросов (distributed query processing) Обработка распределенных транзакций (distributed transaction processing) Независимость от оборудования (hardware independence) Независимость от операционных систем (operating system independence) Прозрачность сети (network independence) Независимость от баз данных (database independence)
Слайд 45Локальная автономия
Узлы в распределённой системе должны быть независимы, или автономны. Локальная независимость означает, что все операции на узле контролируются этим узлом.
Слайд 46Независимость от центрального узла
В идеальной системе все узлы равноправны и независимы, а их базы являются равноправными поставщиками данных в общее пространство данных. База данных на каждом из узлов самодостаточна - она включает полный собственный словарь данных и полностью защищена от несанкционированного доступа. В словаре содержится информация о типе данных, месте их размещения и о способе доступа к данным.
Слайд 47Непрерывные операции
Это качество можно трактовать как возможность непрерывного доступа к данным ("24 часа в сутки, семь дней в неделю"). «Данные доступны всегда, а операции над ними выполняются непрерывно». Обработка, выполняемая в локальном узле БД, не может быть прервана командами из другого узла. Т.е. в каждом узле обработка выполняется независимо и целиком.
Слайд 48Прозрачность расположения
Пользователь ничего не должен знать о реальном, физическом размещении данных в узлах информационной системы. Все операции над данными выполняются без учета их местонахождения. Транспортировка запросов к базам данных осуществляется встроенными системными средствами. Изменение места хранения данных не ведет к изменению работающих с этими данными приложений.
Слайд 49Прозрачная фрагментация
возможность распределенного размещения данных, логически представляющих собой единое целое. Существует фрагментация двух типов: горизонтальная - хранение строк одной таблицы на различных узлах вертикальная - распределение столбцов логической таблицы по нескольким узлам.
Слайд 50Прозрачность тиражирования
Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы. Тиражирование возможно и достигается внутрисистемными средствами. Это свойство СУБД позволяет создавать в узлах сети дубли данных без снижения производительности приложения и без нарушения непротиворечивости данных.
Слайд 51Обработка распределенных запросов
Это возможность выполнения операций выборки над распределенной базой данных, сформулированных в рамках обычного запроса на языке SQL. То есть операцию выборки из DDB можно сформулировать с помощью тех же языковых средств, что и операцию над локальной базой данных. Например,
Слайд 52Обработка распределенных транзакций
Транзакция, изменяющая данные на нескольких узлах сети, называется глобальной или распределенной транзакцией. Распределенная транзакция включает в себя несколько локальных транзакций, каждая из которых завершается двумя путями — фиксируется или прерывается. Распределенная транзакция фиксируется только в том случае, когда зафиксированы все локальные транзакции, ее составляющие.
Слайд 53Независимость от оборудования
Это свойство означает, что в качестве узлов распределенной системы могут выступать компьютеры любых моделей и производителей - от мэйнфреймов до "персоналок".
Слайд 54Независимость от операционных систем
Это качество вытекает из предыдущего и означает многообразие операционных систем, управляющих узлами распределенной системы.
Слайд 55Прозрачность сети
Доступ к любым базам данных может осуществляться по сети. В распределенной системе возможны любые сетевые протоколы.
Слайд 56Независимость от СУБД
Это качество означает, что в распределенной системе могут сосуществовать СУБД различных производителей, и возможны операции поиска и обновления в базах данных различных моделей и форматов.
 Слайд 1
Слайд 1 Слайд 2
Слайд 2 Слайд 3
Слайд 3 Слайд 4
Слайд 4 Слайд 5
Слайд 5 Слайд 6
Слайд 6 Слайд 7
Слайд 7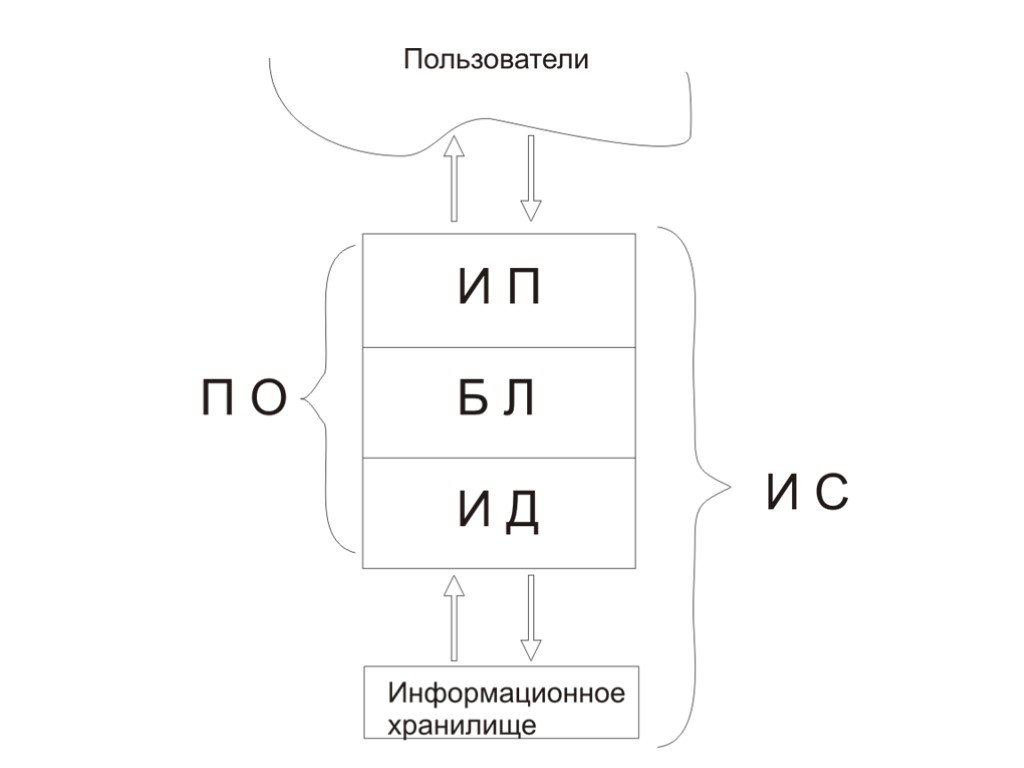 Слайд 8
Слайд 8 Слайд 9
Слайд 9 Слайд 10
Слайд 10 Слайд 11
Слайд 11 Слайд 12
Слайд 12 Слайд 13
Слайд 13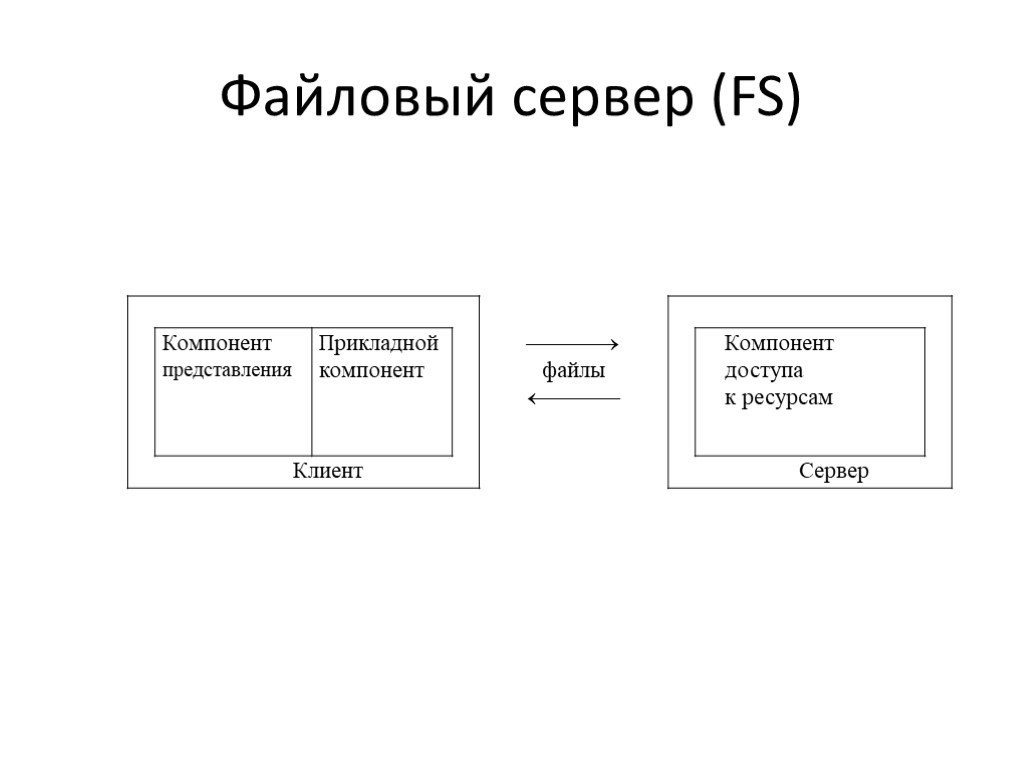 Слайд 14
Слайд 14 Слайд 15
Слайд 15 Слайд 16
Слайд 16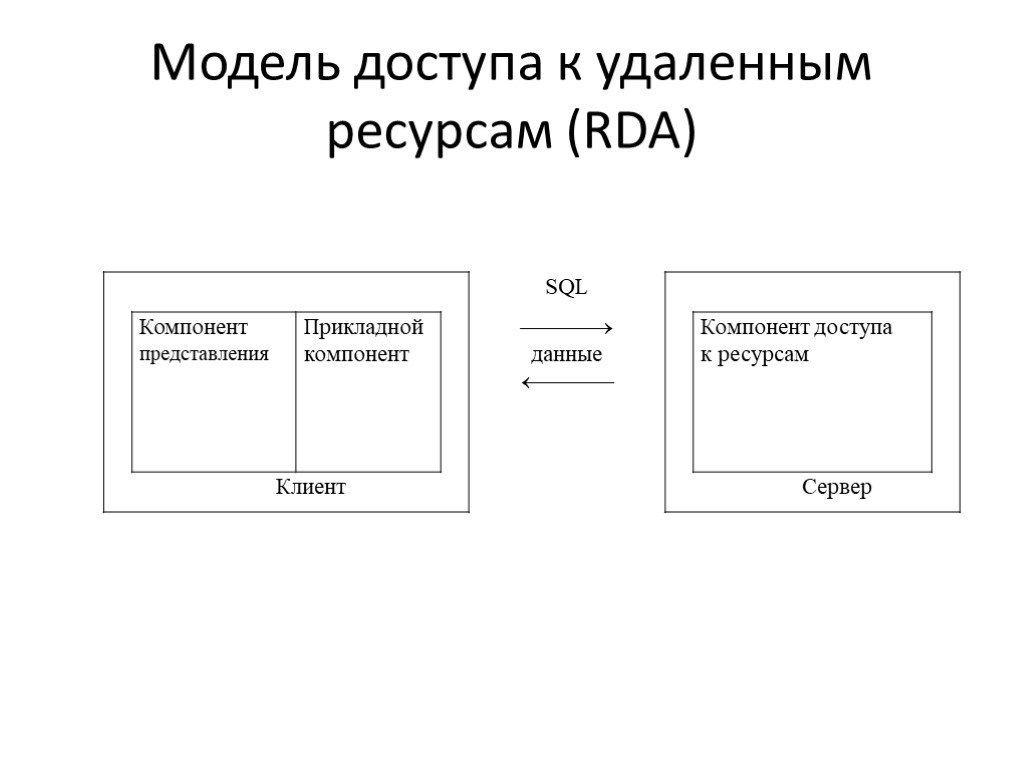 Слайд 17
Слайд 17 Слайд 18
Слайд 18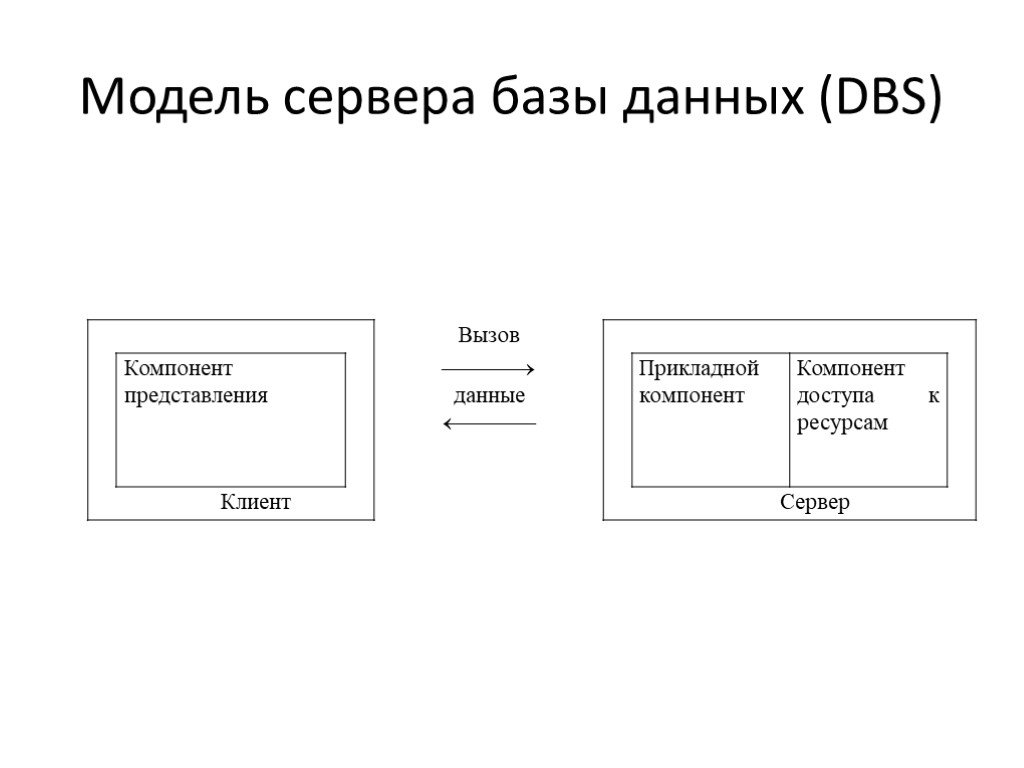 Слайд 19
Слайд 19 Слайд 20
Слайд 20 Слайд 21
Слайд 21 Слайд 22
Слайд 22 Слайд 23
Слайд 23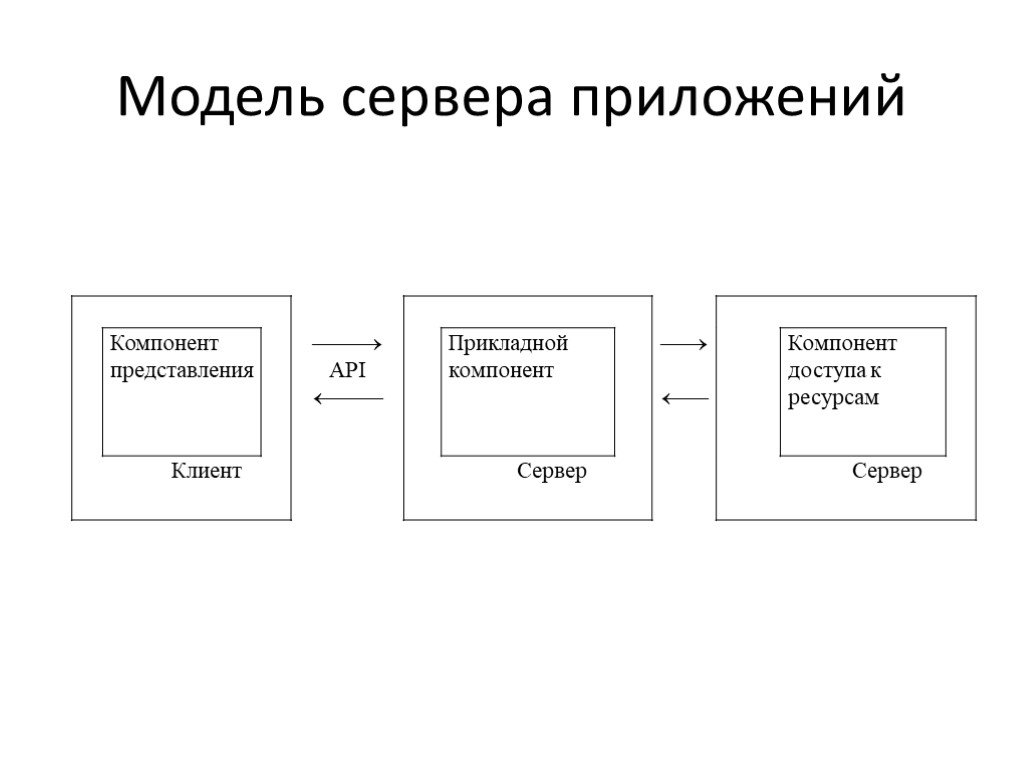 Слайд 24
Слайд 24 Слайд 25
Слайд 25 Слайд 26
Слайд 26 Слайд 27
Слайд 27 Слайд 28
Слайд 28 Слайд 29
Слайд 29 Слайд 30
Слайд 30 Слайд 31
Слайд 31 Слайд 32
Слайд 32 Слайд 33
Слайд 33 Слайд 34
Слайд 34 Слайд 35
Слайд 35 Слайд 36
Слайд 36 Слайд 37
Слайд 37 Слайд 38
Слайд 38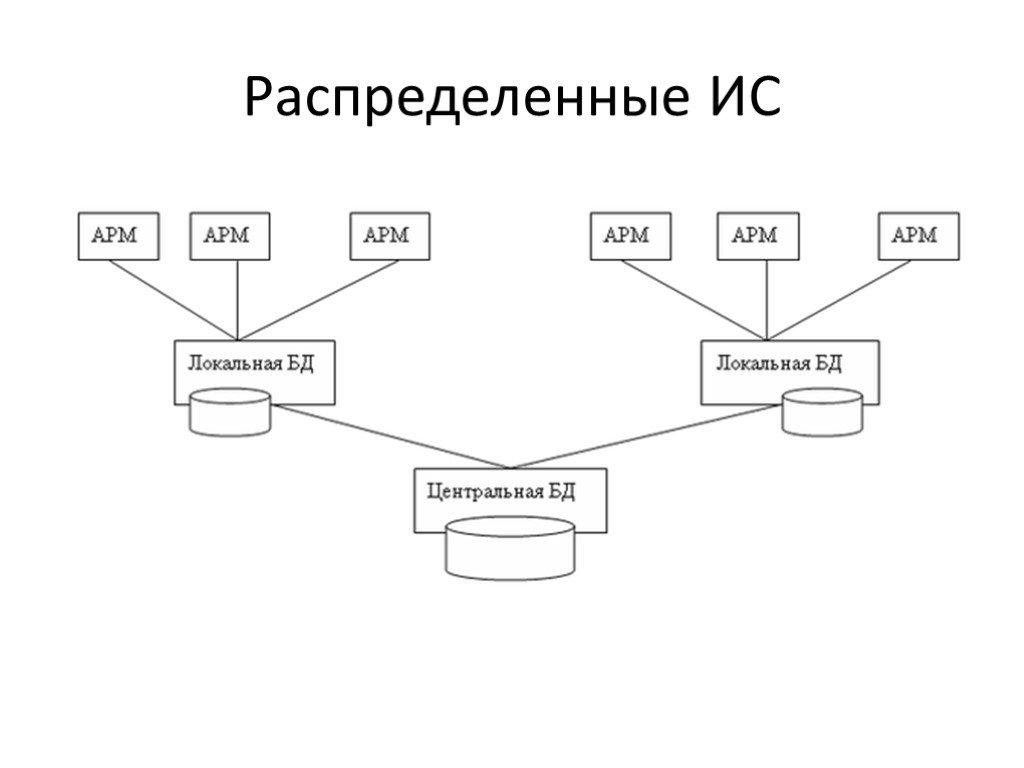 Слайд 39
Слайд 39 Слайд 40
Слайд 40 Слайд 41
Слайд 41 Слайд 42
Слайд 42 Слайд 43
Слайд 43 Слайд 44
Слайд 44 Слайд 45
Слайд 45 Слайд 46
Слайд 46 Слайд 47
Слайд 47 Слайд 48
Слайд 48 Слайд 49
Слайд 49 Слайд 50
Слайд 50 Слайд 51
Слайд 51 Слайд 52
Слайд 52 Слайд 53
Слайд 53 Слайд 54
Слайд 54 Слайд 55
Слайд 55 Слайд 56
Слайд 56




























