Слайд 1Информационные системы в менеджменте
Системы Поддержки процессов Принятия Решений
Слайд 2Структура системы управления
Любого типа упорядоченность возникает в результате какого-то воздействия окружающей среды на систему. Система, приспосабливаясь к изменяющимся условиям, накапливает полезную для себя информацию, повышает уровень своей организованности. По существу, вся содержащаяся в системе структурная информация вводится окружающей средой, и ее изменение (саморазвитие) обусловлено в основном длительным влиянием среды. Таким образом, структуру системы можно рассматривать как связанную, внутреннюю информацию, которая возникает во втором контуре управления в результате циркуляции оперативной информации в первом контуре управления.
Слайд 3Первый контур системы управления {Y(t)→U10(t)} обеспечивает стабилизацию выходов Y(t) объекта (гомеостазис) и отвечает за его эволюционное развитие. Второй контур управления {Y(t)→U20(t)→U21(t)}, накапливая информацию о входах {X(t), U10(t), U20(t)} и выходах {Y(t)} объекта, обеспечивает его революционное (скачкообразное) развитие.
Слайд 4Процесс управления организацией
Объект управления
Учет Анализ Планирование Регулирование факт ситуация альтернативы показатели решение задания цели

Слайд 5Технология управления
Учет – процесс получения объективной информации о складывающейся на объекте ситуации путем сбора фактических значений параметров и их обработки по заданным алгоритмам. Анализ – процесс генерирования альтернатив на основании складывающейся на объекте ситуации и желаемых значений параметров, задаваемых ЛПР на фазе «Планирование», с одной стороны, и постановка диагноза и выявление причин отклонения движения системы от заданной траектории, с другой стороны. Регулирование – процесс формирования и контроль исполнения заданий предприятию и его подразделениям для реализации выбранного на фазе «Планирование» решения.
Технологию управления представим в виде совокупности четырех основных функций менеджмента: планирование, учет, анализ и регулирование Планирование – процесс принятия решения, которое вырабатывается на основе целей, формулируемых вышестоящей организацией, и альтернатив, генерируемых на фазе «Анализ».
. Информационные системы (оперативного) управления ‑ ИСУ (Management Information System ‑ MIS) предназначены для автоматиза")
Слайд 6История ИС для разработки управленческих решений
Первыми стали информационные системы, предназначенные для обработки электронных данных – СОД (Electronic Data Processing – EDP). Информационные системы (оперативного) управления ‑ ИСУ (Management Information System ‑ MIS) предназначены для автоматизации таких функций, как: учет, регулирование и частично функции анализа. Система поддержки принятия решений ‑ СППР (Decision Support System – DSS) представляет собой вид информационной системы, предназначенной для помощи менеджеру при решении плохо структурированных задач, возникающих в процессе принятия решений Экспертные системы (ЭС) представляют собой раздел искусственного интеллекта и используются в СППР для повышения производительности и качества принимаемых решений. Стратегические информационные системы – СИС корпоративного типа (Enterprise Strategic System - ESS) предназначены для оказания помощи высшему руководству компании (Top Managers) в процессе поддержки принятия стратегических решений.

Слайд 7Стратификация КИС по уровням управления
Слайд 8
Слайд 9Структура экспертной системы поддержки принятия решения
Слайд 10СППР (DSS) - это
компьютерная автоматизированная система, целью которой является помощь лицам, принимающим решение в сложных условиях, для полного и объективного анализа предметной деятельности; совокупность процедур по обработке данных и суждений, помогающих руководителю в принятии решений, основанная на использовании моделей; интерактивные автоматизированные системы, помогающие лицу, принимающему решения, использовать данные и модели для решения слабо структурированных проблем; система, которая обеспечивает пользователям доступ к данным и/или моделям, так что они могут принимать лучшие решения.
Слайд 11Разновидности существующих ИС для СППР
Слайд 12
Слайд 13Современные Системы Поддержки Принятия Решений
являются результатом мультидисциплинарного исследования и включают теории: баз данных (Data Base ‑ DB) и баз знаний (Data Knowledge – DK); искусственного интеллекта (Artificial Intelligence ‑ AI); интерактивных компьютерных систем; методов имитационного моделирования и др. возникли в результате слияния управленческих информационных систем и систем управления базами данных и знаний. Современные СППР используют следующие информационные технологии: хранилища данных (Data Warehouse ‑ DW); средства оперативной (в реальном масштабе времени) аналитической обработки информации (On-Line Analytical Processing ‑ OLAP); средства извлечения данных – (Data Mining ‑ DM), текстов (Text Mining – TM) и визуальных образов (Image Mining – IM).

Слайд 14Предназначение СППР
СППР использует и данные, и модели; СППР предназначены для помощи менеджерам в принятии решений для слабоструктурированных и неструктурированных задач; СППР поддерживают, а не заменяют, выработку решений менеджерами; Цель СППР — улучшение эффективности решений.
Слайд 15Классификации СППР
Пассивной СППР называется система, которая помогает процессу принятия решения, но не может вынести предложение, какое решение принять. Активная СППР может сделать предложение, какое решение следует выбрать. Кооперативная позволяет ЛПР изменять, пополнять или улучшать решения, предлагаемые системой, посылая затем эти изменения в систему для проверки. Система изменяет, пополняет или улучшает эти решения и посылает их опять пользователю. Процесс продолжается до получения согласованного решения.
, поддерживает группу пользователей, работающих над выполнением общей задачи. 2. СППР, управляющие данными (Data-Driven DSS) или СППР, ориентированные на работу с данными (Data-oriented DSS) в основном ориентирую")
Слайд 161. СППР, управляющие сообщениями (Communication-Driven DSS, ранее групповая СППР — GDSS), поддерживает группу пользователей, работающих над выполнением общей задачи. 2. СППР, управляющие данными (Data-Driven DSS) или СППР, ориентированные на работу с данными (Data-oriented DSS) в основном ориентируются на доступ и манипуляции с данными. 3. СППР, управляющие документами (Document-Driven DSS), управляют, осуществляют поиск и манипулируют неструктурированной информацией, заданной в различных форматах. 4. СППР, управляющие знаниями (Knowledge-Driven DSS), обеспечивают решение задач в виде фактов, правил, процедур. 5. СППР, управляющие моделями (Model-Driven DSS), характеризуются в основном доступом и манипуляциями с математическими моделями (статистическими, финансовыми, оптимизационными, имитационными). 6. Отметим, что некоторые OLAP-системы, позволяющие осуществлять сложный анализ данных, могут быть отнесены к гибридным СППР, которые обеспечивают моделирование, поиск и обработку данных.

Слайд 17Оперативные СППР предназначены для немедленного реагирования на изменения текущей ситуации в управлении финансово-хозяйственными процессами компании. Стратегические СППР ориентированы на анализ значительных объемов разнородной информации, собираемых из различных источников. Важнейшей целью этих СППР является поиск наиболее рациональных вариантов развития бизнеса компании с учетом влияния различных факторов, таких как конъюнктура целевых для компании рынков, изменения финансовых рынков и рынков капиталов, изменения в законодательстве и др. СППР первого типа получили название Информационных Систем Руководства (Executive Information Systems ‑ EIS). По сути, они представляют собой конечные наборы отчетов, построенных на основании данных из транзакционной информационной системы предприятия, в идеале адекватно отражающих в режиме реального времени основные аспекты производственной и финансовой деятельности. СППР второго типа предполагают достаточно глубокую проработку данных, специально преобразованных так, чтобы их было удобно использовать в ходе процесса принятия решений. Неотъемлемым компонентом СППР этого уровня являются правила принятия решений, которые на основе агрегированных данных дают возможность менеджерам компании обосновывать свои решения, использовать факторы устойчивого роста бизнеса компании и снижать риски. Технологии этого типа строятся на принципах многомерного представления и анализа данных (OLAP).

Слайд 18Архитектура СППР: Функциональная СППР

Слайд 19Функциональная СППР
Функциональная СППР является наиболее простой с архитектурной точки зрения. Такие системы часто встречаются на практике, в особенности в организациях с невысоким уровнем аналитической культуры и недостаточно развитой информационной инфраструктурой. Характерной чертой функциональной СППР является то, что анализ осуществляется с использованием данных из оперативных систем. Преимущества: Быстрое внедрение за счет отсутствия этапа перегрузки данных в специализированную систему Минимальные затраты за счет использования одной платформы Недостатки: Единственный источник данных, потенциально сужающий круг вопросов, на которые может ответить система Оперативные системы характеризуются очень низким качеством данных с точки зрения их роли в поддержке принятия стратегических решений. В силу отсутствия этапа очистки данных, данные функциональной СППР, как правило, обладают невысоким качеством Большая нагрузка на оперативную систему. Сложные запросы могут привести к остановке работы оперативной системы, что весьма нежелательно

Слайд 20Архитектура СППР: Независимые витрины данных

Слайд 21Независимые витрины данных
Независимые витрины данных часто появляются в организации исторически и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий. Преимущества: Витрины данных можно внедрять достаточно быстро Витрины проектируются для ответов на конкретный ряд вопросов Данные в витрине оптимизированы для использования определенными группами пользователей, что облегчает процедуры их наполнения, а также способствует повышению производительности Недостатки: Данные хранятся многократно в различных витринах данных. Это приводит к дублированию данных и, как следствие, к увеличению расходов на хранение и потенциальным проблемам, связанным с необходимостью поддержания непротиворечивости данных Потенциально очень сложный процесс наполнения витрин данных при большом количестве источников данных Данные не консолидируются на уровне предприятия, таким образом, отсутствует единая картина бизнеса

Слайд 22Архитектура СППР: Двухуровневое хранилище данных
Слайд 23Двухуровневое хранилище данных
Двухуровневое хранилище данных строится централизованно для предоставления информации в рамках компании. Для поддержки такой архитектуры необходима выделенная команда профессионалов в области хранилищ данных.Это означает, что вся организация должна согласовать все определения и процессы преобразования данных. Преимущества: Данные хранятся в единственном экземпляре Минимальные затраты на хранение данных Отсутствуют проблемы, связанные с синхронизацией нескольких копий данных Данные консолидируются на уровне предприятия, что позволяет иметь единую картину бизнеса Недостатки: Данные не структурируются для поддержки потребностей отдельных пользователей или групп пользователей Возможны проблемы с производительностью системы Возможны трудности с разграничением прав пользователей на доступ к данным
Слайд 24Архитектура СППР: Трехуровневое хранилище данных

Слайд 25Трехуровневое хранилище данных
Хранилище данных представляет собой единый централизованный источник корпоративной информации. Витрины данных представляют подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса. Преимущества: Создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных Витрины данных синхронизированы и совместимы с корпоративным представлением. Имеется корпоративная модель данных. Существует возможность сравнительно лёгкого расширения хранилища и добавления новых витрин данных Гарантированная производительность Недостатки: Существует избыточность данных, ведущая к росту требований на хранение данных Требуется согласованность с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу)
 информационный поиск; 2) интеллектуальный анализ данных; 3) извлечение (поиск) знаний в базах данных; 4) рассуждение")
Слайд 26Методы поддержки принятия решений
Для поддержки принятия решений c помощью информационных технологий, включая анализ и выработку альтернатив, в СППР используются следующие методы: 1) информационный поиск; 2) интеллектуальный анализ данных; 3) извлечение (поиск) знаний в базах данных; 4) рассуждение на основе прецедентов; 5) имитационное моделирование; 6) генетические алгоритмы; 7) искусственные нейронные сети; 8) методы искусственного интеллекта
 (англ. Information retrieval) — процесс поиска неструктурированной документальной информации и наука об этом поиске. Термин «информационный поиск» был впервые введён Кельвином Муром в 1948 в его докторской диссертации, опубликован и употребляется в лит")
Слайд 27Информационный поиск
Информационный поиск (ИП) (англ. Information retrieval) — процесс поиска неструктурированной документальной информации и наука об этом поиске. Термин «информационный поиск» был впервые введён Кельвином Муром в 1948 в его докторской диссертации, опубликован и употребляется в литературе с 1950. Сначала системы автоматизированного информационного поиска, или информационно-поисковые системы (ИПС), использовались лишь для управления информационным взрывом в научной литературе. Многие университеты и публичные библиотеки стали использовать ИПС для обеспечения доступа к книгам, журналам и другим документам. Широкое распространение ИПС получили с появлением сети Интернет. У русскоязычных пользователей наибольшей популярностью пользуются поисковые системы Google, Yandex и Rambler.
 — выявление скрытых закономерностей или взаимосвязей между переменными в больших массивах необработанных данных. Подразделяется на задачи классификации, моделирования и прогнозирования и другие. Термин «Data Mining» в")
Слайд 28Интеллектуальный анализ данных
Интеллектуальный анализ данных (англ. Data Mining) — выявление скрытых закономерностей или взаимосвязей между переменными в больших массивах необработанных данных. Подразделяется на задачи классификации, моделирования и прогнозирования и другие. Термин «Data Mining» введен Григорием Пятецким-Шапиро в 1989 году. Английский термин «Data Mining» не имеет однозначного перевода на русский язык (добыча данных, вскрытие данных, информационная проходка, извлечение данных/информации) поэтому в большинстве случаев используется в оригинале. Наиболее удачным непрямым переводом считается термин «интеллектуальный анализ данных». Data Mining включает методы и модели статистического анализа и машинного обучения, дистанцируясь от них в сторону автоматического анализа данных. Инструменты Data Mining позволяют проводить анализ данных предметными специалистами (аналитиками), не владеющими соответствующими математическими знаниями.
 знаний в базах данных (Knowledge Discovery in Databases – KDD) ‑ процесс обнаружения полезных знаний в базах данных. Эти знания могут быть представлены в виде закономерностей, правил, прогнозов, связей между элементами данных и др. Главным инструм")
Слайд 29Извлечение знаний в базах данных
Извлечение (поиск) знаний в базах данных (Knowledge Discovery in Databases – KDD) ‑ процесс обнаружения полезных знаний в базах данных. Эти знания могут быть представлены в виде закономерностей, правил, прогнозов, связей между элементами данных и др. Главным инструментом поиска знаний в процессе KDD являются аналитические технологии Data Mining, реализующие задачи классификации, кластеризации, регрессии, прогнозирования, предсказания и т.д. Однако, в соответствии с концепцией KDD, эффективный процесс поиска знаний не ограничивается их анализом. KDD включает последовательность операций, необходимых для поддержки аналитического процесса. К ним относятся: Консолидация данных. Подготовка анализируемых выборок данных. Очистка данных от факторов, мешающих их корректному анализу. Трансформация – оптимизация данных. Анализ данных – применение методов и технологий Data Mining Интерпретация и визуализация результатов анализа, их применение в бизнес-приложениях.
 является подходом, позволяющим решить новую задачу, используя или адаптируя решение уже изве")
Слайд 30Рассуждение на основе прецедентов
Прецедент ‑ случай, имевший место ранее и служащий примером или оправданием для последующих случаев подобного рода. Вывод на основе прецедентов (CBR – Case-Based Reasoning) является подходом, позволяющим решить новую задачу, используя или адаптируя решение уже известной задачи. Как правило, такие методы рассуждений включают в себя четыре основных этапа, образующие так называемый цикл рассуждения на основе прецедентов или CBR-цикл. Основная цель использования аппарата прецедентов в рамках СППР и, в частности, систем экспертной диагностики сложных объектов, заключается в выдаче готового решения ЛПР для текущей ситуации на основе прецедентов, которые уже имели место в прошлом при управлении данным объектом или процессом.

Слайд 31Имитационное моделирование
Имитационное моделирование — это метод, позволяющий строить модели, описывающие процессы так, как они проходили бы в действительности. Такую модель можно «проиграть» во времени как для одного испытания, так и заданного их множества. При этом результаты будут определяться случайным характером процессов. По этим данным можно получить достаточно устойчивую статистику. Имитационное моделирование — это метод исследования, при котором изучаемая система заменяется моделью с достаточной точностью описывающей реальную систему и с ней проводятся эксперименты с целью получения информации об этой системе. Экспериментирование с моделью называют имитацией (имитация — это постижение сути явления, не прибегая к экспериментам на реальном объекте). Имитационное моделирование — это частный случай математического моделирования. Существует класс объектов, для которых по различным причинам не разработаны аналитические модели, либо не разработаны методы решения полученной модели. В этом случае математическая модель заменяется имитатором или имитационной моделью.
 — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путем последовательного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическу")
Слайд 32Генетические алгоритмы
Генетический алгоритм (англ. genetic algorithm) — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путем последовательного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений (англ. evolutionary computation). Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе. Описание алгоритма. Задача кодируется таким образом, чтобы её решение могло быть представлено в виде вектора («хромосома»). Случайным образом создаётся некоторое количество начальных векторов («начальная популяция»). Они оцениваются с использованием «функции приспособленности», в результате чего каждому вектору присваивается определённое значение («приспособленность»), которое определяет вероятность выживания организма, представленного данным вектором. После этого с использованием полученных значений приспособленности выбираются векторы (селекция), допущенные к «скрещиванию». К этим векторам применяются «генетические операторы» (в большинстве случаев «скрещивание» - crossover и «мутация» - mutation), создавая таким образом следующее «поколение». Особи следующего поколения также оцениваются, затем производится селекция, применяются генетические операторы и т. д.
 — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении")
Слайд 33Искусственные нейронные сети
Искусственные нейронные сети (ИНС) — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге при мышлении, и при попытке смоделировать эти процессы. Первой такой моделью мозга был перцептрон. Впоследствии эти модели стали использовать в практических целях, как правило, в задачах прогнозирования. С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и т. п. С математической точки зрения обучение нейронных сетей, это многопараметрическая задача нелинейной оптимизации. С точки зрения кибернетики, нейронная сеть используется в задачах адаптивного управления и как алгоритмы для робототехники. С точки зрения развития вычислительной техники и программирования, нейронная сеть — способ решения проблемы эффективного параллелизма. А с точки зрения искусственного интеллекта, ИНС является основой философского течения коннективизма и основным направлением в структурном подходе по изучению возможности построения (моделирования) естественного интеллекта с помощью компьютерных алгоритмов.
 (англ. Artificial intelligence, AI) — это наука и разработка интеллектуальных машин и систем, особенно интеллектуальных компьютерных программ, направленных на то, чтобы понять человеческий интеллект. При этом используемые методы не обяза")
Слайд 34Методы искусственного интеллекта
Искусственный интеллект (ИИ) (англ. Artificial intelligence, AI) — это наука и разработка интеллектуальных машин и систем, особенно интеллектуальных компьютерных программ, направленных на то, чтобы понять человеческий интеллект. При этом используемые методы не обязаны быть биологически правдоподобны. Но проблема состоит в том, что неизвестно какие вычислительные процедуры мы хотим называть интеллектуальным. А так как мы понимаем только некоторые механизмы интеллекта, то под интеллектом в пределах этой науки мы понимаем только вычислительную часть способности достигнуть целей в мире. Единого ответа на вопрос чем занимается искусственный интеллект, не существует. Почти каждый автор, пишущий книгу об ИИ, отталкивается в ней от какого-либо определения, рассматривая в его свете достижения этой науки. Обычно эти определения сводятся к следующим: тест Тьюринга; когнитивное моделирование; логический подход; агентно- ориентированный подход.
 Слайд 1
Слайд 1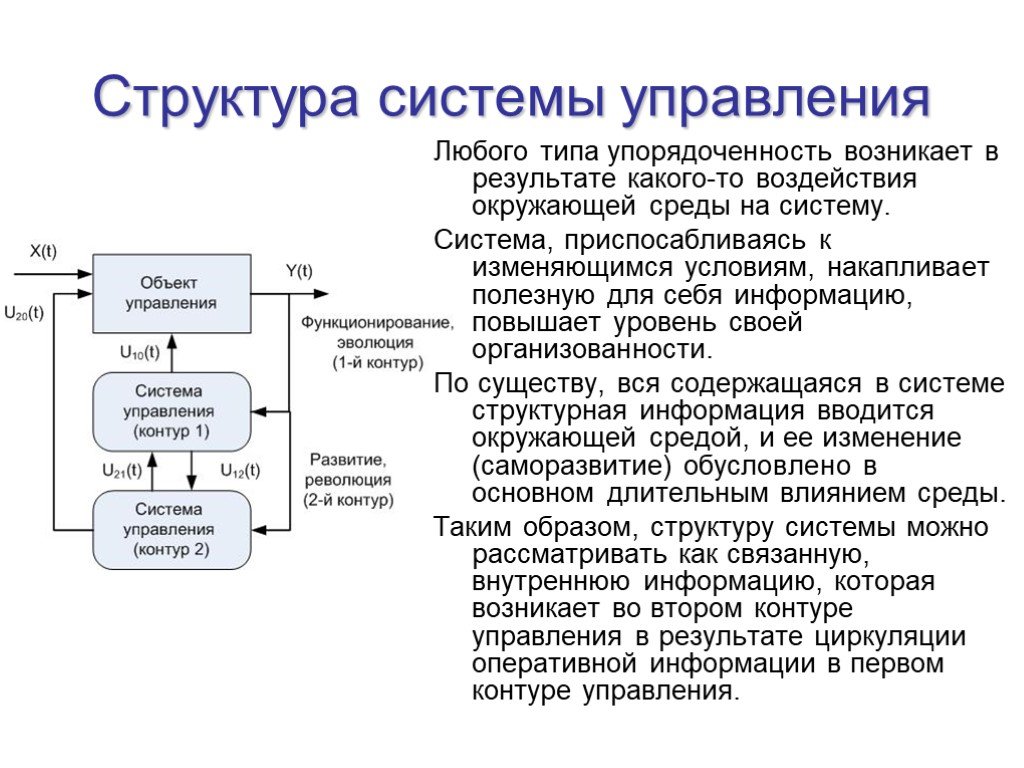 Слайд 2
Слайд 2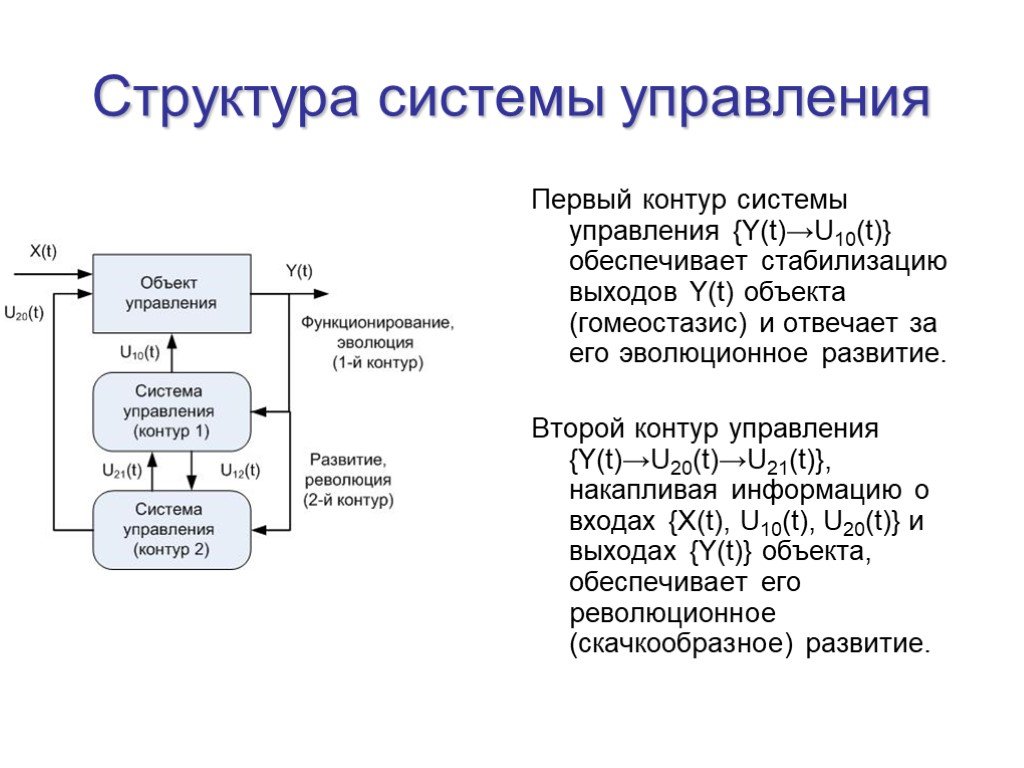 Слайд 3
Слайд 3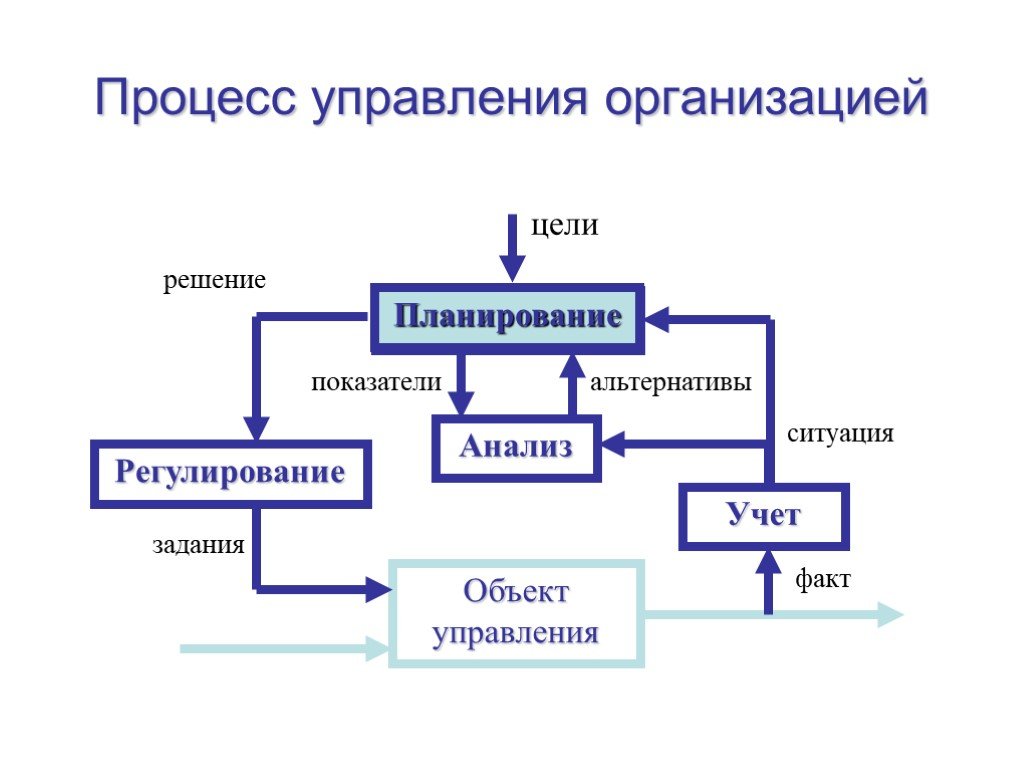 Слайд 4
Слайд 4 Слайд 5
Слайд 5 Слайд 6
Слайд 6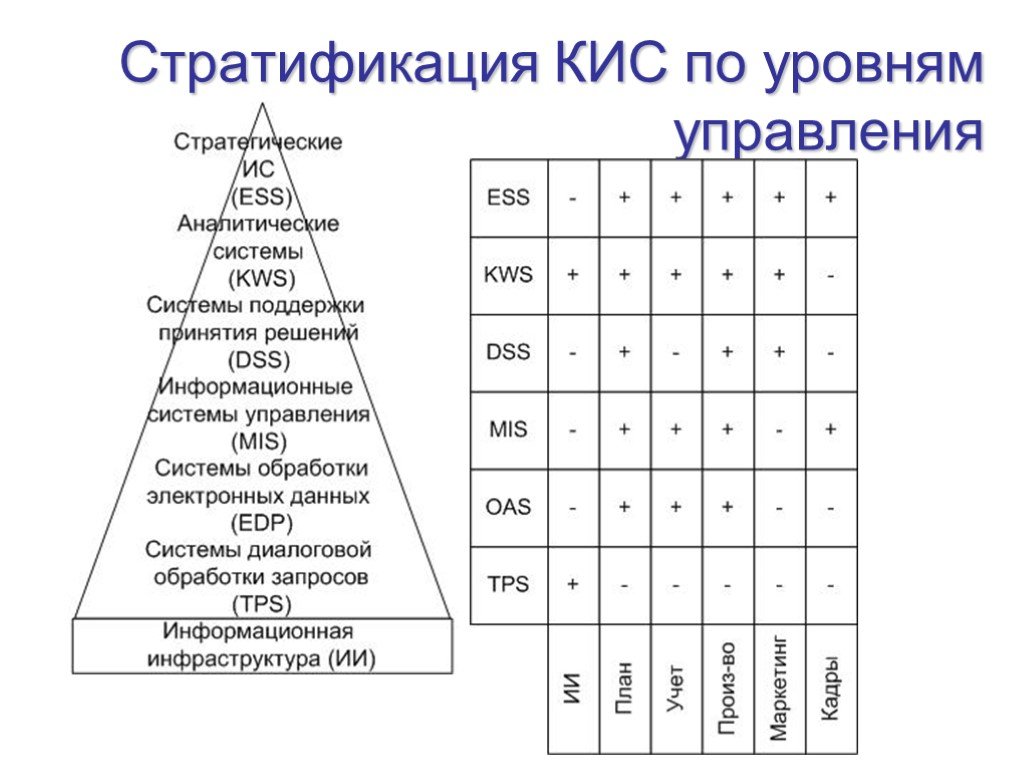 Слайд 7
Слайд 7 Слайд 8
Слайд 8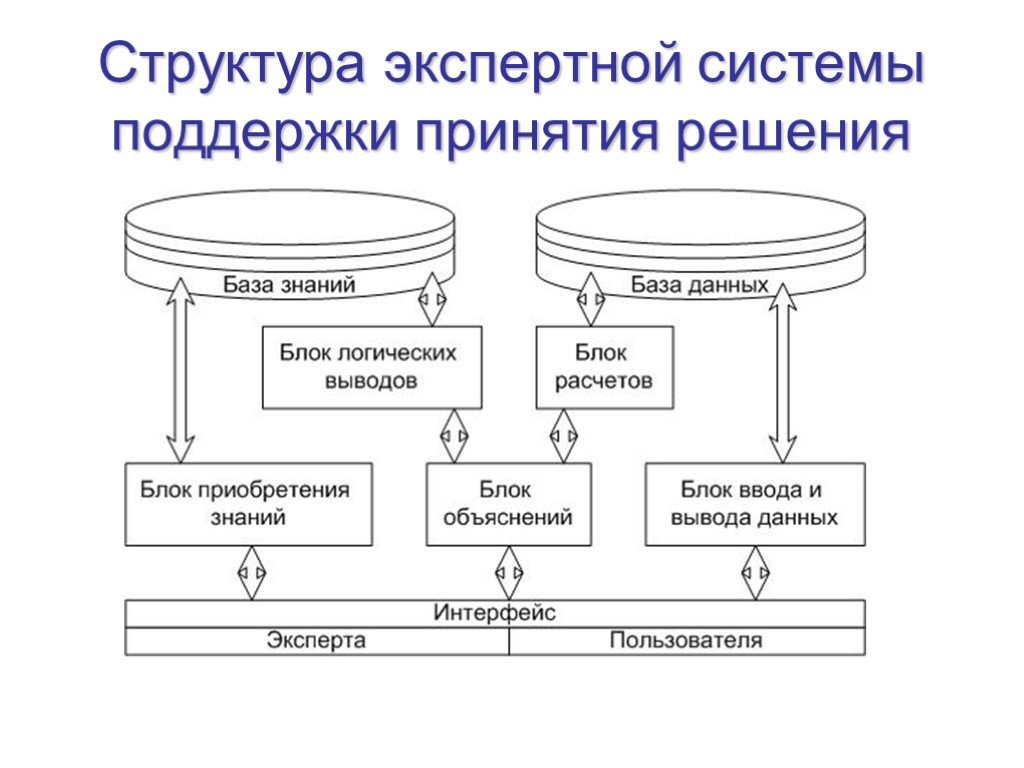 Слайд 9
Слайд 9 Слайд 10
Слайд 10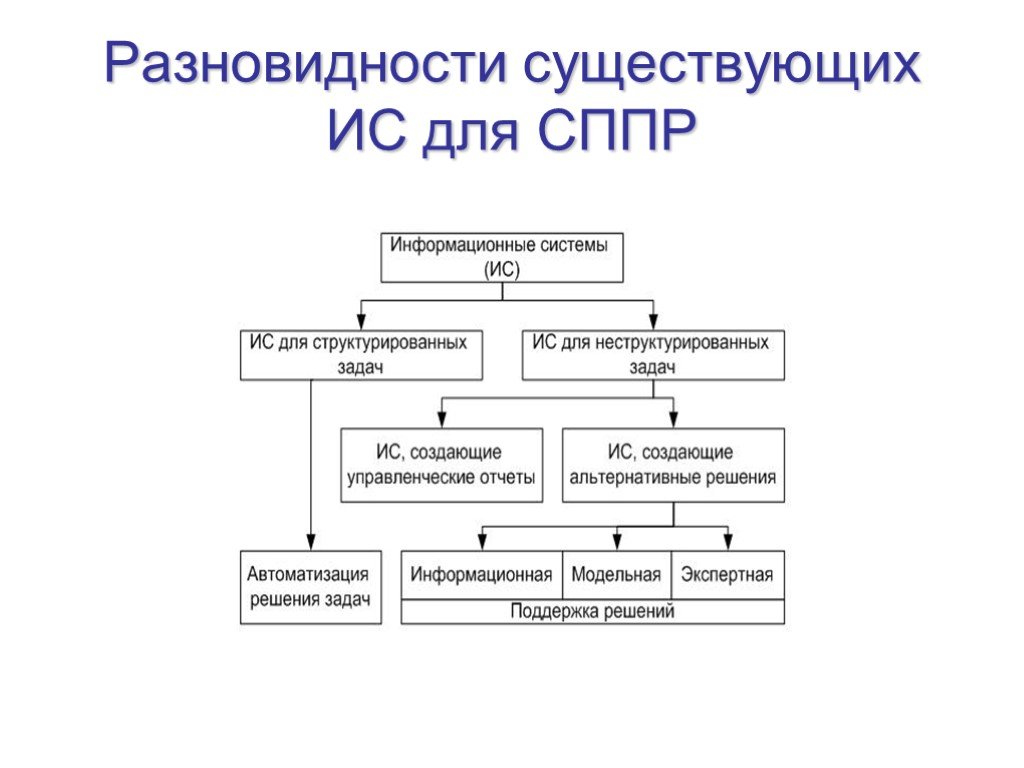 Слайд 11
Слайд 11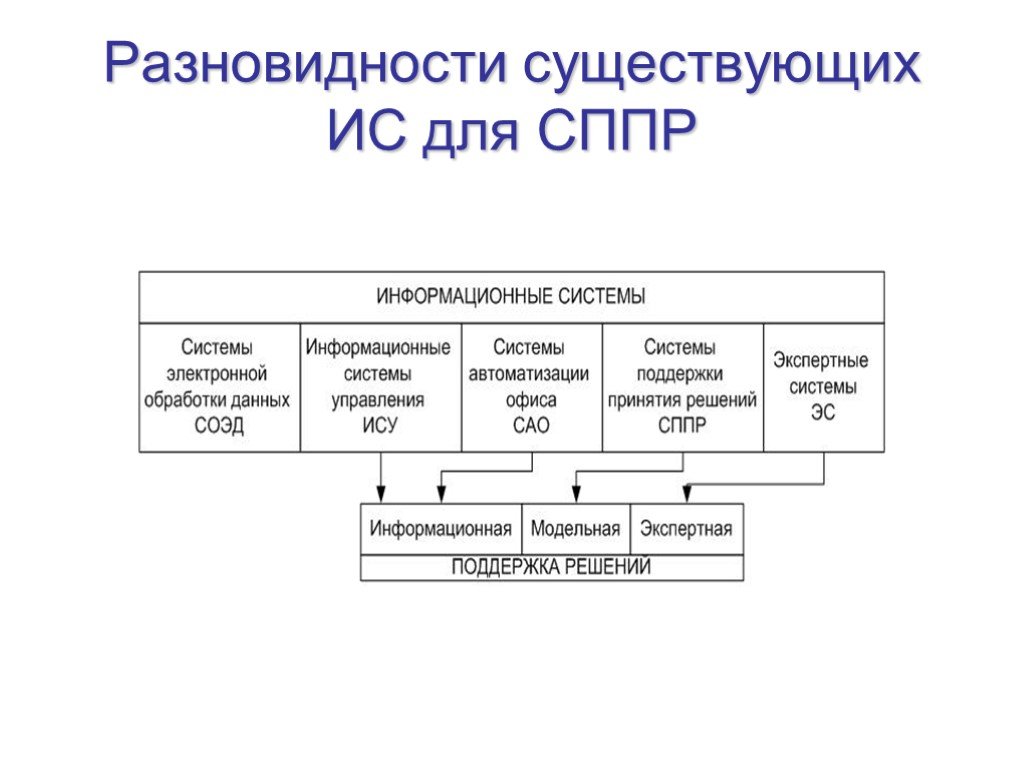 Слайд 12
Слайд 12 Слайд 13
Слайд 13 Слайд 14
Слайд 14 Слайд 15
Слайд 15 Слайд 16
Слайд 16 Слайд 17
Слайд 17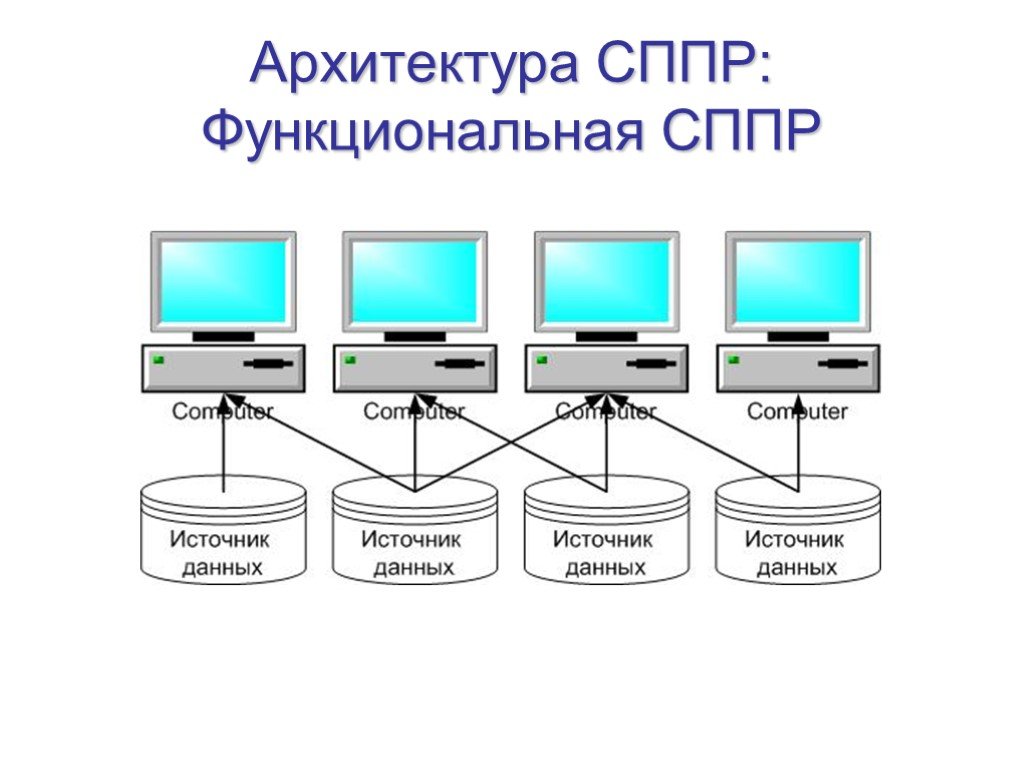 Слайд 18
Слайд 18 Слайд 19
Слайд 19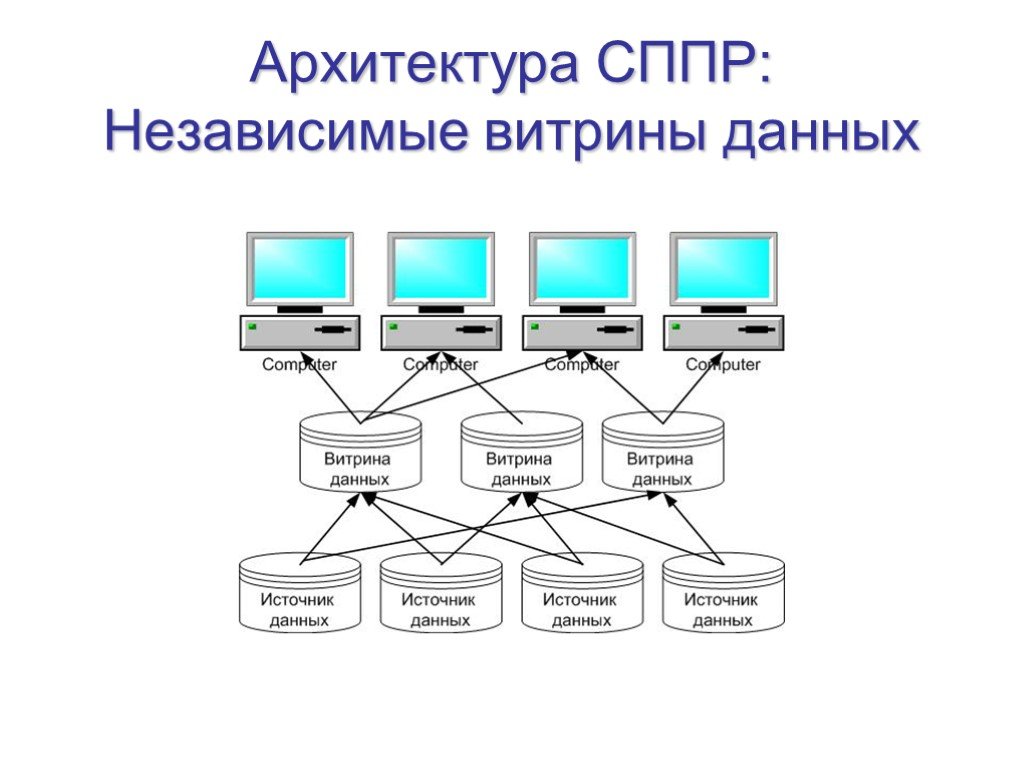 Слайд 20
Слайд 20 Слайд 21
Слайд 21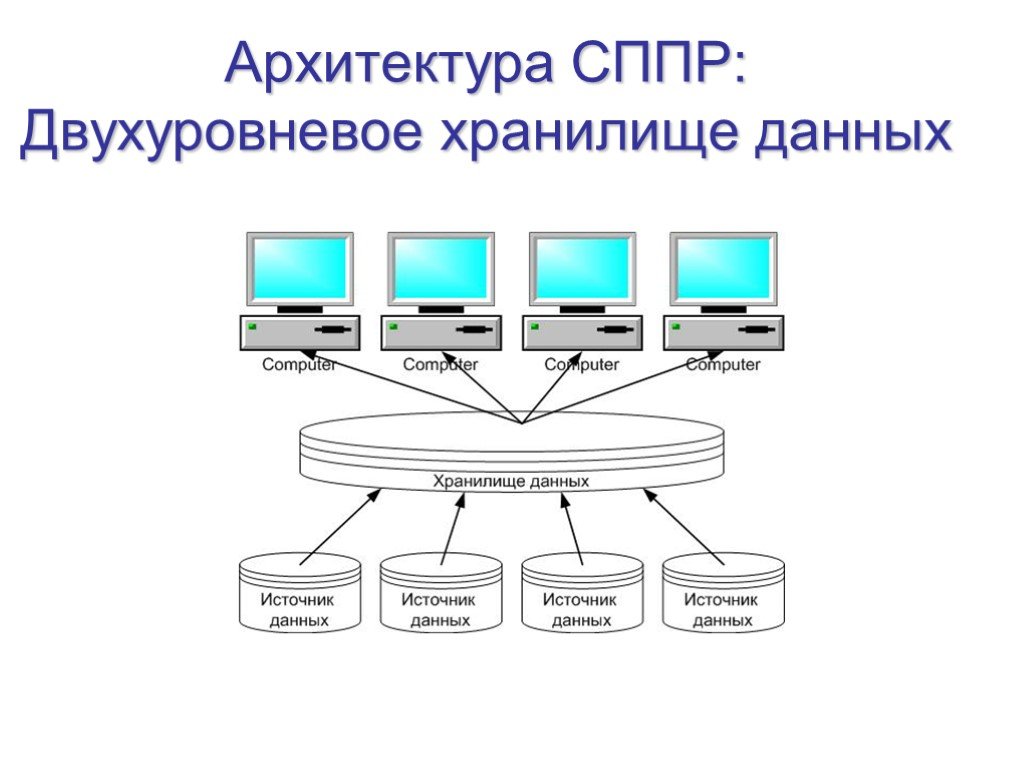 Слайд 22
Слайд 22 Слайд 23
Слайд 23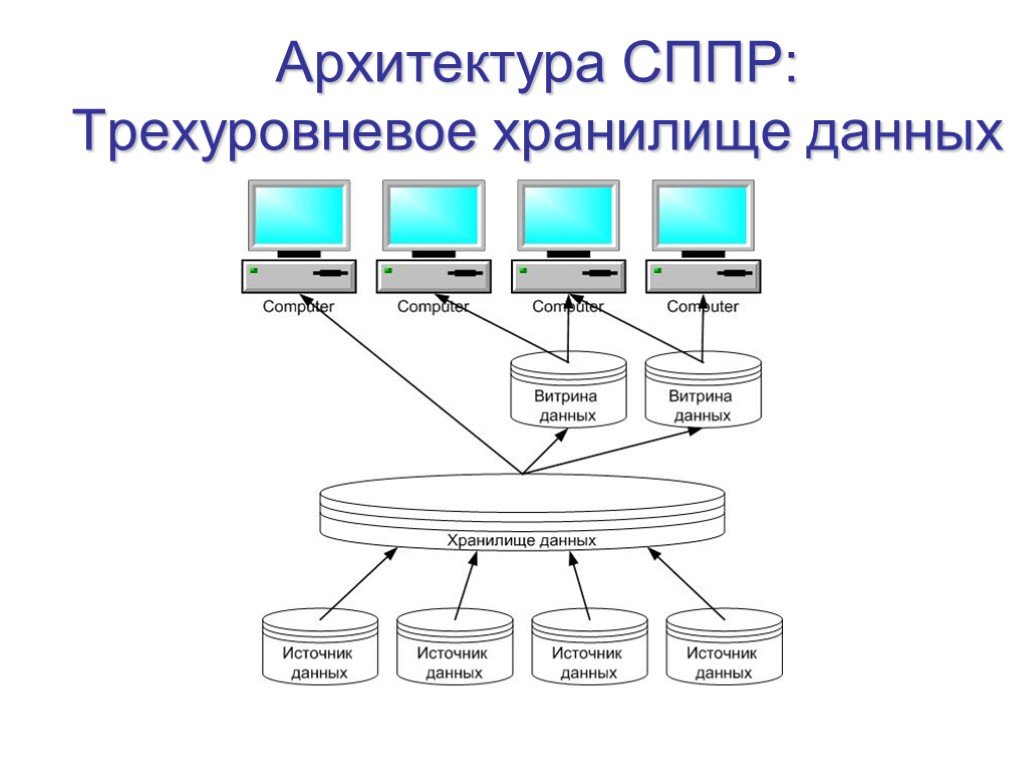 Слайд 24
Слайд 24 Слайд 25
Слайд 25 Слайд 26
Слайд 26 Слайд 27
Слайд 27 Слайд 28
Слайд 28 Слайд 29
Слайд 29 Слайд 30
Слайд 30 Слайд 31
Слайд 31 Слайд 32
Слайд 32 Слайд 33
Слайд 33 Слайд 34
Слайд 34




























