Слайд 1Лекция № 1 Дата: Преподаватель: Евстифеева Наталья Александровна
СУБД ORACLE
Слайд 2Пример логической схемы базы данных
Телефоны Номер Тип
Владелец ФИО Дата рождения Пол
Адрес Страна Город Улица Дом Корпус Квартира
Логическая схема БД Телефонный справочник:
Пример:
Слайд 3Пример физической схемы базы данных
Физическая схема БД Телефонный справочник:
Слайд 4Определение БД
База данных состоит из таблиц, которые связаны между собой с помощью так называемых ключей.
Понятие целостности данных заключается в том, что данные: Корректны; Непротиворечивы; Уникальны.
Слайд 5Автоматизированные системы (АС)
Автоматизированные системы (АС) — это организованная совокупность средств, методов и мероприятий, используемых для регулярной обработки информации для решения задачи. Две черты, характерные для современных АС: - разнообразие задач, решаемых различными пользователями на общей базе данных; - постоянное улучшение аппаратных средств, предназначенных для хранения и обработки данных.
Слайд 6Физической независимостью данных называют возможность изменения физической организации данных без перестройки прикладных программ и логической структуры данных.
Логической независимостью называют возможность изменения логической структуры данных без изменения существующих прикладных программ и технологии обработки данных.
Необходимое условие существования СУБД
Необходимым условием существования СУБД является реализация принципа логической и физической независимости представления данных.
Слайд 7Виды СУБД ORACLE Microsoft Access DB2 и другие
Слайд 8Архитектура сервера ORACLE
Слайд 9Архитектура сервера ORACLE (1)
Разделяемый пул (Shared Pool) содержит кэш библиотек, кэш словаря и управляющие структуры сервера (такие как набор символов БД). Размер выделяемого пула определяется параметром SHARED_POOL_SIZE в файле init.ora. Производительность всей системы в целом зависит от функционирования кэш-буфера данных. Все данные первым делом загружаются в кэш-буфер. В них же выполняется и любое обновление данных.Размер кэш-буфера определяется двумя параметрами настройки DB_BLOCK_SIZE и DB_BLOCK_BUFFERS в файле init.ora. Общий объем кэш-буфера(в байтах) равен произведению DB_BLOCK_SIZE*DB_BLOCK_BUFFERS. Буфер журнала транзакций представляет собой циклический буфер. Размер буфера журнала транзакций задается, параметром LOG_BUFFER, файла init.ora.

Слайд 10Процессы ORACLE
Для работы сервера Oracle должны быть активными системные и пользовательские процессы Oracle. К обязательным процессам относятся: - PMON – монитор процессов; - SMON – системный монитор; - DBWR – процесс записи в базу данных; - LGWR – процесс записи в журнал. Также должны существовать пользовательские процессы. Процессы в ходе своей работы используют файлы, совокупность которых является физическим представлением базы данных.
. PMON - (Process Monitor) осуществляет контроль за состоянием подключений к БД. SMON - после запуска БД выполняет автоматическое восстановление экземпляра. Процессы SMON, PMON должны быть запущены при старте БД, иначе она не будет функционировать. DBWR - (DataBase Writ")
Слайд 11Архитектура сервера ORACLE (2)
PMON - (Process Monitor) осуществляет контроль за состоянием подключений к БД. SMON - после запуска БД выполняет автоматическое восстановление экземпляра. Процессы SMON, PMON должны быть запущены при старте БД, иначе она не будет функционировать. DBWR - (DataBase Writer) отвечает за перенос обновленных блоков и производит перезапись в следующих случаях: -Обнаружена контрольная точка. -Количество элементов в dirty - списке достигло заданной величины - половина значения параметра DB_BLOCK_WRITE_BATCH из файла init.ora. -Количество использованных буферов достигло величины, заданной параметром DB_BLOCK_MAX_SCAN из файла init.ora. -Истек заданный для процесса DBWR интервал времени (3 с).LGWR LGWR производит перезапись информации из буфера журнала транзакций, которая находится в ГСО (SGA), в файлы оперативного журнала при условии, что: -Транзакция принимается. -Буфер журнала транзакций заполняется на треть. -Процесс DBWR завершает перезапись данных из кэш буфера после обнаружения контрольной точки.
. ARCH - (Archiver) - отвечает за копирование полностью заполненного оперативного файла журнала транзакций, в архивные файлы журнала транзакций. Для того, чтобы запустить это процесс нужно установить параметр ARCHIV_LOG_START в файле init.ora в значение TRUE. CKPT - отв")
Слайд 12Архитектура сервера ORACLE (3)
ARCH - (Archiver) - отвечает за копирование полностью заполненного оперативного файла журнала транзакций, в архивные файлы журнала транзакций. Для того, чтобы запустить это процесс нужно установить параметр ARCHIV_LOG_START в файле init.ora в значение TRUE. CKPT - отвечает за обработку контрольных точек. CKPT необходим для того, чтобы снизить нагрузку на LGWR. RECO - (Recovery) - отвечает за восстановление незавершенных транзакций. Он запускается автоматически, если система сконфигурирована для распределенных транзакций. За это отвечает параметр DISTRIBUTED_TRANSACTION в файле init.ora.
. SNPn - выполняет автоматическое обновление снимков БД (snapshot). Так же запускает процедуры в соответствии с расписанием, зафиксированным в пакете DBMS_JOB. Параметр JOB_QUEUE_PROCESS в файле init.ora задает количество запускаемых процессов SNPn, а параметр JOB_QUEUE")
Слайд 13Архитектура сервера ORACLE (4)
SNPn - выполняет автоматическое обновление снимков БД (snapshot). Так же запускает процедуры в соответствии с расписанием, зафиксированным в пакете DBMS_JOB. Параметр JOB_QUEUE_PROCESS в файле init.ora задает количество запускаемых процессов SNPn, а параметр JOB_QUEUE_INTERVAL длительность в течении, которой процесс "засыпает" прежде чем выполнить задание. LCKn - координирует блокировки устанавливаемые разными экземплярами БД. Pnnn - это процесс параллельных запросов. Сервер Oracle запускает и останавливает процессы Pnnn в зависимости от активности работы БД и настройки опций параллельных запросов. Эти процессы принимают участие в формировании компонентов БД. Количество запущенных процессов, определяется параметрами PARALLEL_MIN_SERVERS и PARALLEL_MAX_SERVERS соответственно.
Слайд 14Группы файлов
Существуют три основные группы файлов, составляющие базу данных:
Контрольные файлы –описаны типы файлов, а контрольные относятся к управляющим.
Слайд 15Структура памяти
Память, используемая сервером Oracle, имеет следующую структуру: SGA(system global area) – системная память для всей базы данных. Все системные и пользовательские процессы могут обращаться к данной области памяти. Для процессов Oracle выделяет отдельную область – PGA (process global area).
Слайд 16Понятие экземпляра
Экземпляр – это совокупность процессов, разделяющих определенную область памяти и управляющих одной или несколькими базами данных. Обычно существует один экземпляр для базы данных, хотя возможна работа нескольких экземпляров с одним набором файлов базы данных. Каждый экземпляр может управлять одной или несколькими базами данных. Каждая конкретная база данных имеет собственное имя и соответствует некоторому экземпляру, под управлением которого она была создана.
Слайд 17Словарь данных
Словарь данных – это база метаданных о собственно базе данных. Информация словаря данных хранится в виде таблиц, над которыми созданы многочисленные представления, и пользователь, обладающий необходимыми правами доступа, может получить необходимую информацию по текущему состоянию базы, используя запросы на языке SQL. Большинство представлений словаря данных доступно любому пользователю и с их помощью можно посмотреть информацию об основных объектах Oracle.
Слайд 18Основные понятия ORACLE
-Таблица (TABLE); -представление (VIEW); -синоним (SYNONYM); -индекс (INDEX); -кластер (CLUSTER); -табличная область (TABLESPACE); -роль (ROLE); -снимок (SNAPSHOT); -связь базы данных (DATABASE LINK); -сегмент отката (ROLBACK SEGMENT).
 – объект, обладающий возможностью создавать и использовать другие объекты Oracle, а также запрашивать выполнение функций сервера. С пользователем Oracle связана схема (SHEMA), которая является логическим набором объектов базы данных, таких, к")
Слайд 19Пользователь, таблицы, представления
Пользователь (USER) – объект, обладающий возможностью создавать и использовать другие объекты Oracle, а также запрашивать выполнение функций сервера. С пользователем Oracle связана схема (SHEMA), которая является логическим набором объектов базы данных, таких, как таблицы, последовательности, синонимы, представления, хранимые программы, принадлежащие этому пользователю. К объектам, не принадлежащим схеме, но хранимых в базе данных, относятся каталоги, профили, роли, сегменты отката, табличные области и пользователи. Схема имеет только одного пользователя-владельца, ответственного за создание и удаление этих объектов. Таблица (TABLE) – является базовой структурой реляционной модели. Полное имя таблицы в базе данных состоит из имени схемы и собственно имени таблицы. Таблицы могут быть связаны между собой отношениями ссылочной целостности. Представление (VIEW) – это поименованная, динамически поддерживаемая сервером выборка из одной или нескольких таблиц. По сути, представление – это производное множество строк, которое является результатом выполнения некоторого запроса к базовым таблицам.
 – это альтернативное имя или псевдоним объекта Oracle, который позволяет пользователям базы данных иметь доступ к данному объекту. Индекс (INDEX) – это объект базы данных, предназначенный для повышения производительности выборки данных.")
Слайд 20Синоним, индекс, кластер, табличная область
Синоним (SYNONYM) – это альтернативное имя или псевдоним объекта Oracle, который позволяет пользователям базы данных иметь доступ к данному объекту. Индекс (INDEX) – это объект базы данных, предназначенный для повышения производительности выборки данных. Индекс создается для столбцов таблицы и обеспечивает более быстрый доступ к данным за счет хранения указателей (ROWID) на местоположение строк. Кластер (CLUSTER) – объект, задающий способ хранения данных нескольких таблиц, содержащих информацию, обычно обрабатываемую совместно, например, значения столбцов таблиц, часто участвующих в эквисоединениях. Табличная область (TABLESPACE) – именованная часть базы данных, используемая для распределения памяти для таблиц, индексов и других объектов.
 – именованная совокупность привилегий, которые могут быть предоставлены пользователям или другим ролям. Снимок (SNAPSHOT) – локальная копия таблицы удаленной базы данных, которая используется либо для тиражирования всей или части таблицы, либо для тир")
Слайд 21Роль, снимок, связь, сегмент отката
Роль (ROLE) – именованная совокупность привилегий, которые могут быть предоставлены пользователям или другим ролям. Снимок (SNAPSHOT) – локальная копия таблицы удаленной базы данных, которая используется либо для тиражирования всей или части таблицы, либо для тиражирования результата запроса данных из нескольких таблиц. Связь базы данных (DATABASE LINK) – это объект базы данных, который позволяет обратиться к объектам удаленной базы данных. Сегмент отката (ROLBACK SEGMENT) – объект базы данных, предназначенный для обеспечения многопользовательской работы. В сегментах отката находятся обновляемые и удаляемые данные в пределах одной транзакции.
; -функция (FUNCTION); -пакет (PACKAGE); -триггер (TRIGGER); -библиотеки (LIBRARY); -типы (TYPE); -каталог")
Слайд 22Объекты ORACLE
Для программирования алгоритмов обработки данных, реализации механизмов динамической поддержки целостности базы данных Oracle используют следующие объекты: -процедура (PROCEDURE); -функция (FUNCTION); -пакет (PACKAGE); -триггер (TRIGGER); -библиотеки (LIBRARY); -типы (TYPE); -каталог (DIRECTORY); -профиль (PROFILE).
Слайд 23Процедура, функция, пакет, триггер
Процедура (PROCEDURE) – это поименованный, структурированный набор конструкций языка PL/SQL, предназначенный для решения конкретной задачи. Функция (FUNCTION) – это поименованный, структурированный набор конструкций языка PL/SQL, предназначенный для решения конкретной задачи и возвращающий значение. Пакет (PACKAGE) – это поименованный, структурированный набор переменных, процедур, функций и других объектов, связанных функциональным замыслом. Триггер (TRIGGER) – это хранимая процедура, которая автоматически выполняется тогда, когда происходит связанное с триггером событие.
 – объекты БД, предназначенные для взаимодействия программ PL/SQL с модулями, написанными на других языках программирования. Типы (TYPE) – новые виды объектов БД, предназначенные для реализации объектных расширений. Каталог (DIRECTORY) – объект,")
Слайд 24Библиотека, тип, каталог, профиль
Библиотеки (LIBRARY) – объекты БД, предназначенные для взаимодействия программ PL/SQL с модулями, написанными на других языках программирования. Типы (TYPE) – новые виды объектов БД, предназначенные для реализации объектных расширений. Каталог (DIRECTORY) – объект, предназначенный для организации файлового ввода-вывода и работы с большими двоичными объектами. Профиль (PROFILE) – объект, ограничивающий использование пользователем системных ресурсов, например процессорного времени или числа операции ввода-вывода.
Слайд 25Лекция № 2 Дата: Преподаватель: Евстифеева Наталья Александровна
Слайд 27Базовая команда SELECT
SELECT *|{ [DISTINCT] column| expression [alias], …} FROM table;
SELECT указывает, какие столбцы; FROM указывает, из какой таблицы.
SELECT список из одного или более столбцов * выбирает все столбцы DISTINCT устраняет дубликаты столбец|выражение выбирает заданный столбец или выражение псевдоним присваивает заданным столбцам другие имена FROM таблица указывает таблицу, содержащую столбцы
Синтаксис:
Слайд 28Выбор всех столбцов
SELECT * FROM departments;
Слайд 29Выбор конкретных столбцов
SELECT department_id, location_id FROM departments;
Слайд 30Неопределённое значение (NULL)
Неопределенное значение (NULL) – это значение, которое недоступно, не присвоено, неизвестно или неприменимо. Это не ноль и не пробел.
SELECT last_name, job_id, salary, commission_pct FROM employees;
Если в строке отсутствует значение какого-либо столбца, считается, что столбец содержит NULL. Неопределенные значения допускаются в столбцах с данными любого типа за исключением случаев, когда столбец был создан с ограничением NOT NULL или PRIMARY KEY.
Слайд 31Использование псевдонима (алиаса) столбца
SELECT last_name AS name, commission_pct comm FROM employees;
SELECT last_name “Name”, salary*12 “Annual Salary” FROM employees;
Слайд 32Устранение строк-дубликатов
Дубликаты устраняются с помощью ключевого слова DISTINCT в команде SELECT.
SELECT DISTINCT department_id FROM employees;
Слайд 33Ограничение количества выбираемых строк
Количество возвращаемых строк можно ограничить с помощью предложения WHERE.
SELECT *|{ [DISTINCT] column/expression [alias],…} FROM table [WHERE condition (s)];
Предложение WHERE следует за предложением FROM.
WHERE ограничивает количество выбираемых строк, задавая условие выборки условие условие, состоящее из имен столбцов, выражений, констант, оператора сравнения
Предложение WHERE может сравнивать значения в столбцах, литералы, арифметические выражения, функции. Предложение WHERE состоит из трех элементов: имя столбца; оператор сравнения; имя столбца, константа или список значений.
Слайд 34Операторы сравнения
WHERE выражение оператор значение
Примеры:
Псевдонимы не могут использоваться в предложении WHERE. Символы != и ^= могут также применяться для проверки условия «не равно».
Слайд 35Другие условия сравнения
Слайд 36Использование условия BETWEEN
Условие BETWEEN используется для вывода строк на основе диапазона значений
SELECT last_name, salary FROM employees WHERE salary BETWEEN 2500 AND 3500;
Слайд 37Использование условия IN
Условие принадлежности IN используется для проверки на вхождение значений в список.
SELECT employee_id, last_name, salary, manager_id FROM employees WHERE manager_id IN (100, 101, 201);
Условие IN может использоваться с данными любого типа. Если в список входят символьные строки и даты, они должны быть заключены в апострофы (‘ ’)
Слайд 38Использование условия LIKE
Условие LIKE используется для поиска символьных значений по шаблону с метасимволами. Условия поискам могут включать алфавитные и цифровые символы: «%» - обозначает ноль или много символов, «_» - обозначает один символ.
SELECT first_name FROM employees WHERE first_name LIKE ‘S%’;
SELECT last_name, hire_date FROM employees WHERE hire_date LIKE ‘%95’;
Слайд 39Логические условия
Слайд 40Приоритеты операторов
Изменить стандартную последовательность можно с помощью круглых скобок, в которые заключаются выражения обрабатываемые первыми.
Слайд 41Предложение ORDER BY
Предложение ORDER BY используется для сортировки строк. В команде SELECT предложение ORDER BY указывается последним.
SELECT last_name, job_id, department_id, hire_date FROM employees ORDER BY hire_date;
ORDER BY (столбец, выражение) [ASC|DESC]
ORDER BY задает порядок вывода выбранных строк ASC упорядочивает строки в порядке возрастания (по умолчанию) DESC упорядочивает строки в порядке убывания
Слайд 42Функции SQL
Функции являются очень мощным средством SQL и используются в следующих целях:
Вычисления над данными; изменение отдельных единиц данных; управление выводом групп строк; форматирование чисел и дат для вывода; преобразование типов данных.
Функции SQL принимают один или несколько аргументов и всегда возвращают значение.
Слайд 43Два типа функций SQL
Однострочные функции Эти функции работают только с одной строкой и возвращают по одному результату для каждой строки. Однострочные функции могут быть разных типов (например: символьные, числовые, для работы с датами, функции преобразования). Многострочные функции Эти функции работают с группой строк и выдают по одному результату для каждой группы. Их часто называют групповыми функциями.
Слайд 44Однострочные функции
Символьные функции: принимают на входе символьные данные, а возвращают как символьные, так и числовые значения. Числовые функции: принимают на входе числовые данные и возвращают числовые значения. Функции преображения: преобразуют значение из одного типа данных в другой.
Функции для обработки дат: работают с значениями типа DATE. Все функции для работы с датами возвращают значение типа DATE за исключением функции MONTH_BETWEEN, которая возвращает число. Общие функции: NVL, NVL2, NULLIF, COALSECE, CASE, DECODE.
Слайд 45Символьные функции (1)
Слайд 46Символьные функции (2) ****
Слайд 47Функции манипулирования символами
Слайд 48Числовые функции
Числовые функции принимают на входе числовые данные и возвращают числовые значения.
Слайд 49Работа с датами
SYSDATE-эта функция, которая возвращает: дату время Вы можете использовать SYSDATE также, как любое другое имя столбца. Например, можно вынести текущую дату при выполнении запроса из таблицы. Обычно выполняют выбор SYSDATE из фиктивной таблицы, имеющий имя DUAL. Пример Вывод текущей даты с использованием таблицы DUAL. SELECT SYSDATE FROM DUAL;
Слайд 50Арифметические операции с датами
Т.к. в базе данных даты хранится в виде чисел, с ними можно выполнять такие арифметические операции, как сложение и вычитание. Прибавлять и вычитать можно как числовые константы, так и даты. Результатом прибавления числа к дате и вычитания числа из даты является дата. Результатом вычитания одной даты из другой является количество дней, разделяющих эти даты. Прибавление часов к дате производится путем деления количества часов на 24. Возможны следующие операции:
Слайд 51Функции для работы с датами
Слайд 52Явное преобразование типов данных (1)
Для преобразования значения из одного типа данных в другой SQL предлагает три функции.
Слайд 53Явное преобразование типов данных (2)
Слайд 54Функция TO_CHAR с датами
TO_CHAR (date, ‘format_model’)
Модель формата: Должна быть заключена в апострофы. Различает символы верхнего и нижнего регистров. Может включать любые разрешенные элементы формата даты. Использует элемент fm для удаления конечных пробелов и ведущих нулей. Отделяется от значения даты запятой. Названия дней и месяцев на выводе автоматически заполняются до нужной длины пробелами. Для удаления вставленных пробелов и ведущих нулей используется элемент fm режима заполнения (fill mode). Изменить ширину выходного символьного столбца можно с помощью команды COLUMN iSQL*Plus.
Слайд 55Элементы формата даты
Слайд 56Использование функции TO_CHAR с числами
Форматы, используемые с функцией TO_CHAR для вывода числового значения в виде символьной строки:
TO_CHAR (число, ‘модель_формата’)
Слайд 57Вложенные функции
Однострочные функции могут быть вложены на любую глубину. Вложенные функции вычисляются от самого глубокого уровня к внешнему.
Слайд 58Общие функции
Эти функции работают с любыми типами данных и используются для обработки неопределенных значений списка выражений.
Слайд 59Выражения CASE
Помогает создавать условные запросы, которые выполняют действия логического оператора IF-THEN-ELSE
CASE выражение WHEN сравн_выражение1 THEN возвр_выражение1 [WHEN сравн_выражение2 THEN вовзр_выражение2 WHEN сравн_выражениеn THEN вовзр_выражениеn ELSE else-выражение] END
Все выражения (выражение, сравн_выражение и возвр_выражение) должны быть одного типа. Допустимые типы: CHAR, VARCHAR2, NCHAR и NVARCHAR2.
![Функция DECODE. Помогает создать условные запросы, которые выполняют действия логического условия CASE или оператора IF-THEN-ELSE. DECODE (столбец|выражение, вариант 1, результат 1 [ , вариант2, результат2…] [ , результат_по_умолчанию]). Функция DECODE расшифровывает столбец или выражение после срав](https://prezentacii.org/upload/cloud/19/09/161409/images/thumbs/screen60.jpg "Функция DECODE. Помогает создать условные запросы, которые выполняют действия логического условия CASE или оператора IF-THEN-ELSE. DECODE (столбец|выражение, вариант 1, результат 1 [ , вариант2, результат2…] [ , результат_по_умолчанию]). Функция DECODE расшифровывает столбец или выражение после срав")
Слайд 60Функция DECODE
Помогает создать условные запросы, которые выполняют действия логического условия CASE или оператора IF-THEN-ELSE.
DECODE (столбец|выражение, вариант 1, результат 1 [ , вариант2, результат2…] [ , результат_по_умолчанию])
Функция DECODE расшифровывает столбец или выражение после сравнения его с каждым искомым значением варианта. Если выражение равно искомому значению, функция возвращает соответствующий результат. Если выражение не совпадает ни с одним из искомых значений, а результат_по_умолчанию не задан, функция возвращет неопределенное значение.
Слайд 61Дополнительные условия поиска с оператором AND
Пример: Чтобы вывести фамилию, номер отдела и местоположение отдела для служащего Matos, требуется дополнительное условие в предложении WHERE.
SELECT last_name, employees.department_id, department_name FROM employess, departments WHERE employees.departmnet_id=departments.department_id AND last_name=‘Matos’;
Слайд 62Использование псевдонимов таблиц
SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id FROM employees e, departmnets d WHERE e.departmnet_id=d.departmnet_id;
-- Псевдонимы таблиц дают альтернативное имя таблице, уменьшают объем кода SQL и, следовательно, экономят память. -- Псевдоним таблиц могут быть длиной до 30 символов; -- Если в предложении FROM для указания таблицы используется псевдоним, этот псевдоним должен использоваться вместо имени таблицы во всем предложении SELECT; -- Следует выбирать осмысленные псевдонимы; -- Действие псевдонима распространяется лишь на текущую команду SELECT.
Слайд 63Соединение более, чем двух таблиц
Для соединения n таблиц требуется, по крайней мере, (n-1) условий соединения
SELECT e.last_name, d.departmnet_name, l.city FROM employees e, departments d, locations l WHERE e.department_id = d.department_id AND d.location_id = l.location_id;
Слайд 64Групповые функции
Групповые функции работают с множеством строк и возвращают один результат на группу.
Максимальный оклад в таблице EMPLOYEES
Слайд 65Типы групповых функций
Слайд 66Синтаксис групповых функций
SELECT [столбец,] групп_функция (столбец), … FROM таблица [WHERE условие] [GROUP BY столбец] [ORDER BY столбец];
-- Если используется слово DISTINCT, дубликаты при вычислениях функции не учитываются. Если используется слово ALL, рассматриваются все значения, включая дубликаты. Слово ALL указывать не обязательно, т.к. оно используется по умолчанию. -- Допустимые типы данных для аргумента: CHAR, VARCHAR2, NUMBER или DATE, если задано выражение. -- Все групповые функции, кроме COUNT(*), игнорируют неопределенные значения. -- Для замены неопределенных значений определенными используются функции NVL, NVL2 и COALESCE. -- Сервер Oracle неявно сортирует данные в порядке возрастания, если используется предложение GROUP BY. Для того, чтобы изменить порядок сортировки, можно использовать опцию DESC после ORDER BY.
, MAX(salary), MIN (salary), SUM(salary) FROM employees WHERE job_id LIKE ‘%REP%’; Функции AVG, SUM, MIN, MAX применяются к столбцам, в которых можно хранить цифровые данные. В примере вычисляются средний, самый высокий, самый низкий оклад и сумма о")
Слайд 67Использование функций AVG и SUM
SELECT AVG(salary), MAX(salary), MIN (salary), SUM(salary) FROM employees WHERE job_id LIKE ‘%REP%’;
Функции AVG, SUM, MIN, MAX применяются к столбцам, в которых можно хранить цифровые данные.
В примере вычисляются средний, самый высокий, самый низкий оклад и сумма окладов всех торговых представителей.
![Исключение групп: предложение HAVING. SELECT [столбец,] групп_функция (столбец), … FROM таблица [WHERE условие] [GROUP BY выражение_группировки] [HAVING ограничивающее_условие] [ORDER BY столбец]; С помощью предложения HAVING их выходных данных исключаются некоторые группы. Сервер Oracle обрабатывае](https://prezentacii.org/upload/cloud/19/09/161409/images/thumbs/screen68.jpg "Исключение групп: предложение HAVING. SELECT [столбец,] групп_функция (столбец), … FROM таблица [WHERE условие] [GROUP BY выражение_группировки] [HAVING ограничивающее_условие] [ORDER BY столбец]; С помощью предложения HAVING их выходных данных исключаются некоторые группы. Сервер Oracle обрабатывае")
Слайд 68Исключение групп: предложение HAVING
SELECT [столбец,] групп_функция (столбец), … FROM таблица [WHERE условие] [GROUP BY выражение_группировки] [HAVING ограничивающее_условие] [ORDER BY столбец];
С помощью предложения HAVING их выходных данных исключаются некоторые группы. Сервер Oracle обрабатывает предложение HAVING следующим образом: Строки группируются. К группе применяется групповая функция. Выводятся группы, удовлетворяющие критериям в предложении HAVING. Предложение HAVING может предшествовать предложению GROUP BY, но логичнее сделать предложение GROUP BY первым. Образование групп и вычисление групповых функций происходят до того, как к группам из списка SELECT применяется предложение HAVING.

Слайд 69Использование предложения HAVING
-- Предложение GROUP BY можно использовать без групповой функции в списке SELECT. -- Для исключения строк после применения групповой функции требуются предложения GROUP BY и HAVING.
В примере выводятся номера отделов и максимальный оклад только тех отделов, где он превышает 10000$;
SELECT department_id, MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary)>10000;
Слайд 70Синтаксис подзапросов
SELECT список_выбора FROM таблица WHERE выражение оператор (SELECT список_выбора FROM таблица);
-- Подзапрос (внутренний запрос) выполняется один раз до главного запроса. -- Результат подзапроса используется главным запросом (внешним запросом). -- Подзапрос можно использовать в таких предложениях языка SQL как WHERE, HAVING, FROM
Слайд 71Многострочные подзапросы
Подзапросы возвращающие более одной строки называются многострочными.
Многострочные подзапросы используют многострочные операторы сравнения.
SELECT last_name, salary, department_id FROM employees WHERE salary IN (SELECT MIN(salary) FROM employees GROUP BY department_id);
Слайд 72Insert
Добавление строк в таблицу с использованием Insert:
INSERT INTO table [ (column [ , column…])] VALUES (value [ , value…])];
Используя такую конструкцию вы сможете добавить только одну строку за раз.
Слайд 73Update
Для обновления существующих строк используется команда UPDATE. В случае необходимости можно одновременно обновлять несколько строк.
UPDATE таблица SET столбец = значение [, столбец=значение, …] [WHERE условие];
Обычно для идентификации отдельной строки используется главный ключ. Использование с этой целью других столбцов может привести к неожиданному обновлению нескольких строк вместо одной.
Слайд 74DELETE
Для удаления строк используется команда DELETE.
DELETE [FROM] таблица [WHERE условие];
Если ни одна строка не была удалена, выдается сообщение “0 rows deleted.”
Слайд 75Использование значений по умолчанию
DEFAULT в команде INSERT:
INSERT INTO departments (department_id, department_name, manager_id) VALUES (300, ‘Engineering’, DEFAULT);
DEFAULT в команде UPDATE:
UPDATE departments SET manager_id=DEFAULT WHERE department_id=10;
Ключевое слово DEFAULT используется для задания значения, которое ранее определено в качестве значения по умолчанию для столбца. Если значение по умолчанию не определено для соответствующего столбца, Oracle устанавливает неопределенное значение.
 псевдоним ON (условие_соединения) WHEN MATCHED THEN UPDATE SET столбец1 = значение_столбца1, столбец2 = значение_")
Слайд 76Синтаксис команды MERGE
Команда MERGE позволяет вставлять или изменять строки при определенных условиях.
MERGE INTO имя_таблицы псевдоним_таблицы USING (таблица|представление|подзапрос) псевдоним ON (условие_соединения) WHEN MATCHED THEN UPDATE SET столбец1 = значение_столбца1, столбец2 = значение_столбца2 WHEN NOT MATCHED THEN INSERT (список_столбцов) VALUES(список_столбцов);
INTO определяет целевую таблицу, в которую производится вставка или изменение USING определяет источники данных, которые используются для изменения или вставки; это может быть таблица, представление или подзапрос ON условие, определяющее действие (изменение или вставка), которое выполняется по команде MERGE WHEN (NOT) MATCHED указывает серверу, как реагировать на результаты условия соединения
![Команда CREATE TABLE. CREATE TABLE [схема.]таблица (столбец тип_данных [DEFAULT выражение] [,…]); Задаётся имя таблицы, имя столбца, тип данных столба и размер столбца. Команда CREATE TABLE языка SQL используется для создания таблиц. Это одна из команд Языка определения данных (DDL). Команды DDL явл](https://prezentacii.org/upload/cloud/19/09/161409/images/thumbs/screen77.jpg "Команда CREATE TABLE. CREATE TABLE [схема.]таблица (столбец тип_данных [DEFAULT выражение] [,…]); Задаётся имя таблицы, имя столбца, тип данных столба и размер столбца. Команда CREATE TABLE языка SQL используется для создания таблиц. Это одна из команд Языка определения данных (DDL). Команды DDL явл")
Слайд 77Команда CREATE TABLE
CREATE TABLE [схема.]таблица (столбец тип_данных [DEFAULT выражение] [,…]);
Задаётся имя таблицы, имя столбца, тип данных столба и размер столбца.
Команда CREATE TABLE языка SQL используется для создания таблиц. Это одна из команд Языка определения данных (DDL). Команды DDL являются подмножеством команд SQL, используемых для создания, изменения и удаления структур базы данных. Эти команды немедленно влияют на базу данных и записывают информацию в словарь данных. Чтобы создать таблицу, пользователь должен иметь привилегию CREATE TABLE и область хранения, где можно создавать объекты.
Слайд 79Лекция № Процедуры/курсоры Дата: Преподаватель: Евстифеева Наталья Александровна
Слайд 80Хранимая процедура
Хранимая процедура — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. У хранимых процедур могут быть входные и выходные параметры и локальные переменные; в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам.
Слайд 81Блок в PL/SQL
Базовой единицей языка PL/SQL является блок (block), который имеет следующую структуру:
Это так называемый анонимный блок. Такой блок компилируется каждый раз при выполнении, не хранится в базе данных и не может быть вызван из другого блока.
Слайд 82Курсоры
Курсор может возвращать одну строку, несколько строк или ни одной строки. Для запросов, возвращающих более одной строки, можно использовать только явный курсор. Для повторного создания результирующего набора для других значений параметров курсор следует закрыть, а затем повторно открыть.
Слайд 83Операторы управления явным курсором
CURSOR выполняет объявление явного курсора. OPEN открывает курсор, создавая новый результирующий набор на базе указанного запроса. FETCH выполняет последовательное извлечение строк из результирующего набора от начала до конца. CLOSE закрывает курсор и освобождает занимаемые им ресурсы
Слайд 84Атрибуты курсора
%ISOPEN — возвращает значение TRUE, если курсор открыт. %FOUND — определяет, найдена ли строка, удовлетворяющая условию. %NOTFOUND — возвращает TRUE, если строка не найдена. %ROWCOUNT — возвращает номер текущей строки.
Слайд 85Последовательность операций с курсорами
Типичная последовательность, при операциях в данном случае с явными (определенными курсорами) будет такая:
Слайд 86Полный синтаксис определения явного курсора
Полный синтаксис определения явного курсора таков:
Слайд 871. Выбрать все заказы: 2. Выбрать несколько столбцов для определенного номера заказа
CURSOR get_orders IS SELECT * FROM ORDERS;
CURSOR get_orders(Pord_num ORDERS.order_num%TYPE) IS SELECT ORDER_DATE, MFR, AMOUNT FROM ORDERS WHERE order_num = Pord_num;
Слайд 883. Получить полную запись для определенного номера заказа 4. Получение имени сотрудника по его номеру
CURSOR get_orders(Pord_num ORDERS.order_num%TYPE) IS SELECT * FROM ORDERS WHERE order_num = Pord_num RETURN ORDERS%ROWTYPE;
CURSOR get_name(empl_nm SALESREPS.empl_num%TYPE) RETURN SALESREPS.name%TYPE IS SELECT name FROM SALESREPS WHERE empl_num = empl_nm;
Слайд 89Оператор FETCH
Выборка данных из курсора производится с помощью оператора FETCH.
FETCH - имя курсора - INTO - список переменных
FETCH - имя курсора - INTO - запись PL/SQL (%ROWTYPE)
Слайд 90Успехов в освоении курса!!!
 Слайд 1
Слайд 1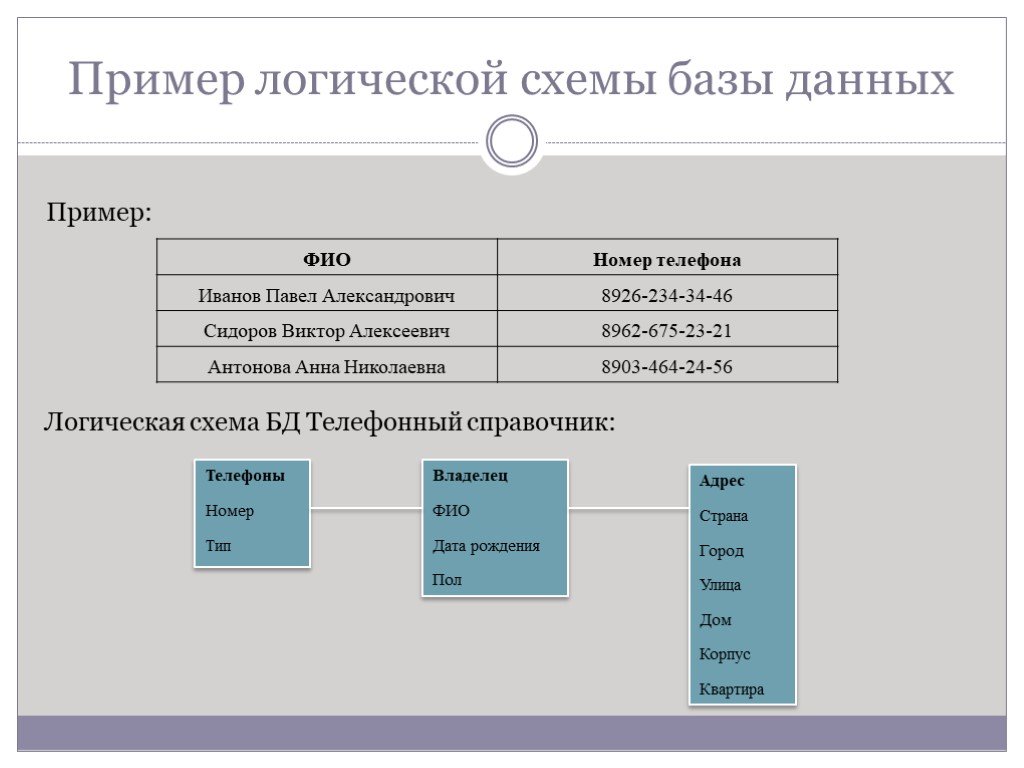 Слайд 2
Слайд 2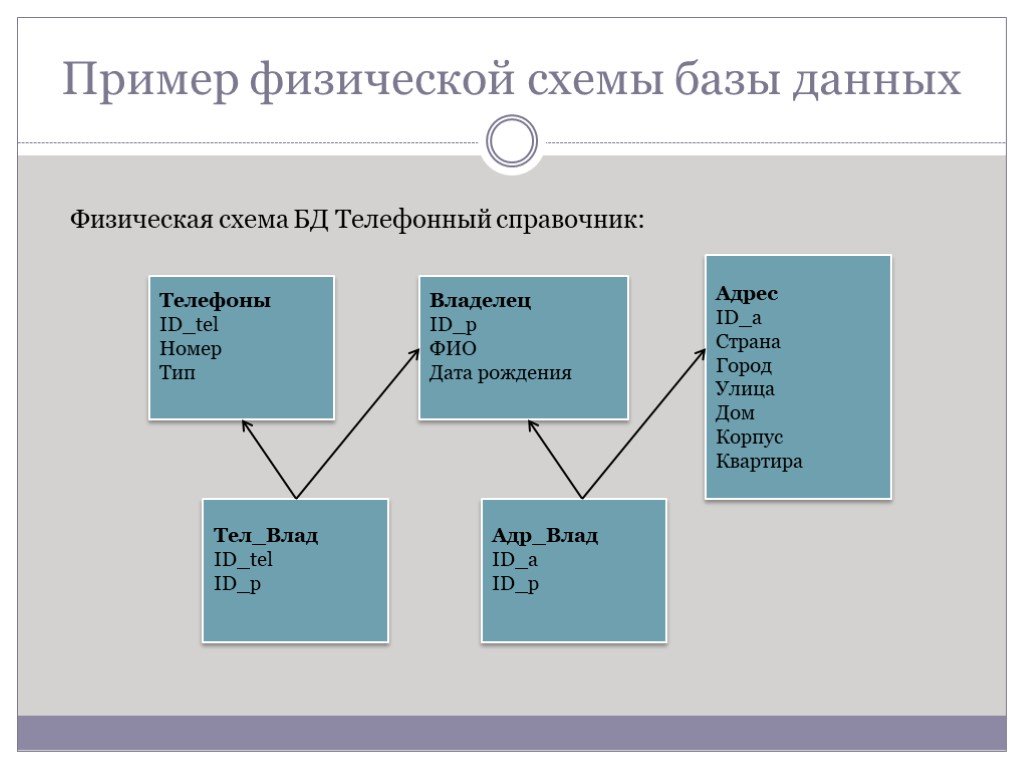 Слайд 3
Слайд 3 Слайд 4
Слайд 4 Слайд 5
Слайд 5 Слайд 6
Слайд 6 Слайд 7
Слайд 7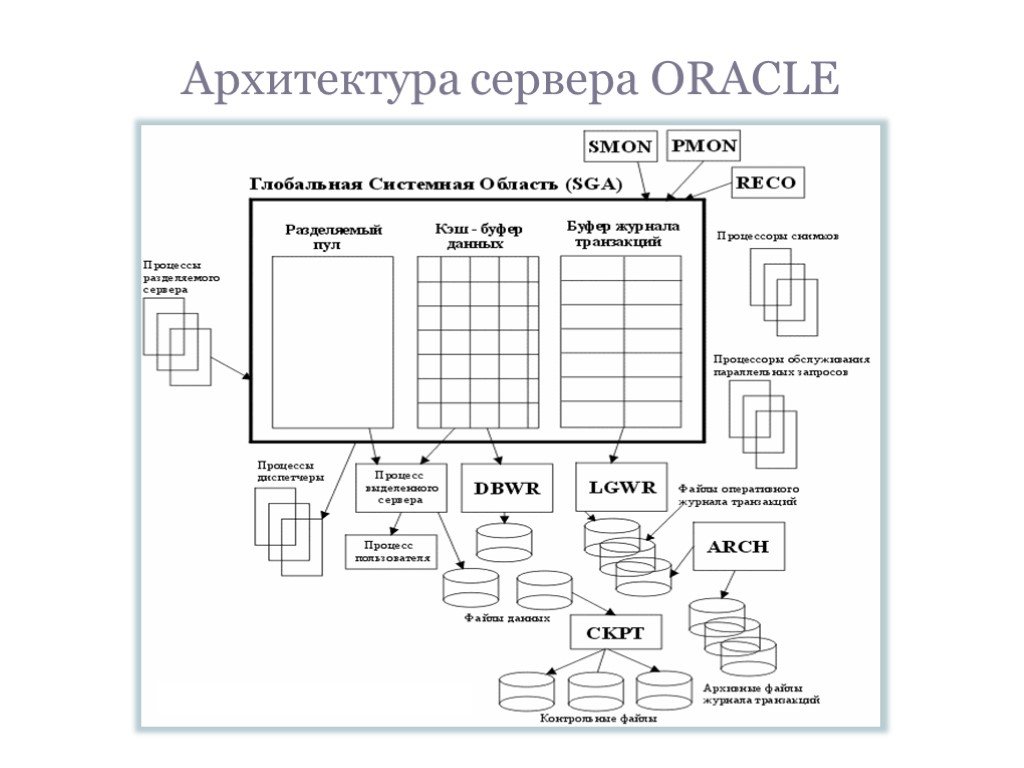 Слайд 8
Слайд 8 Слайд 9
Слайд 9 Слайд 10
Слайд 10 Слайд 11
Слайд 11 Слайд 12
Слайд 12 Слайд 13
Слайд 13 Слайд 14
Слайд 14 Слайд 15
Слайд 15 Слайд 16
Слайд 16 Слайд 17
Слайд 17 Слайд 18
Слайд 18 Слайд 19
Слайд 19 Слайд 20
Слайд 20 Слайд 21
Слайд 21 Слайд 22
Слайд 22 Слайд 23
Слайд 23 Слайд 24
Слайд 24 Слайд 25
Слайд 25 Слайд 26
Слайд 26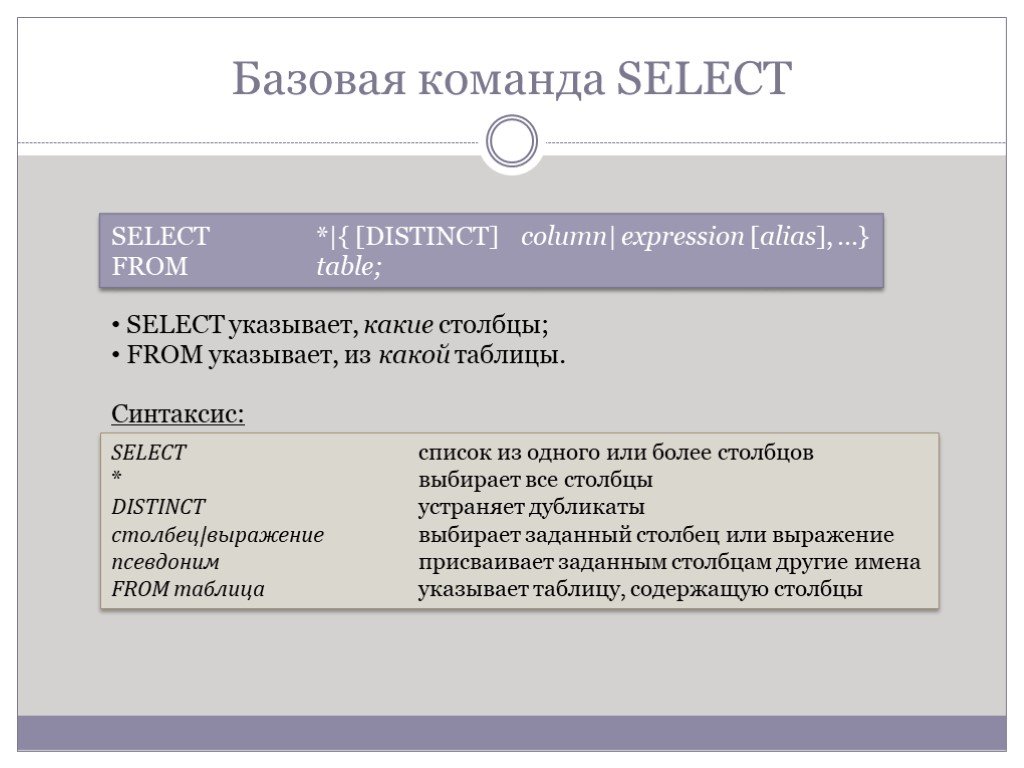 Слайд 27
Слайд 27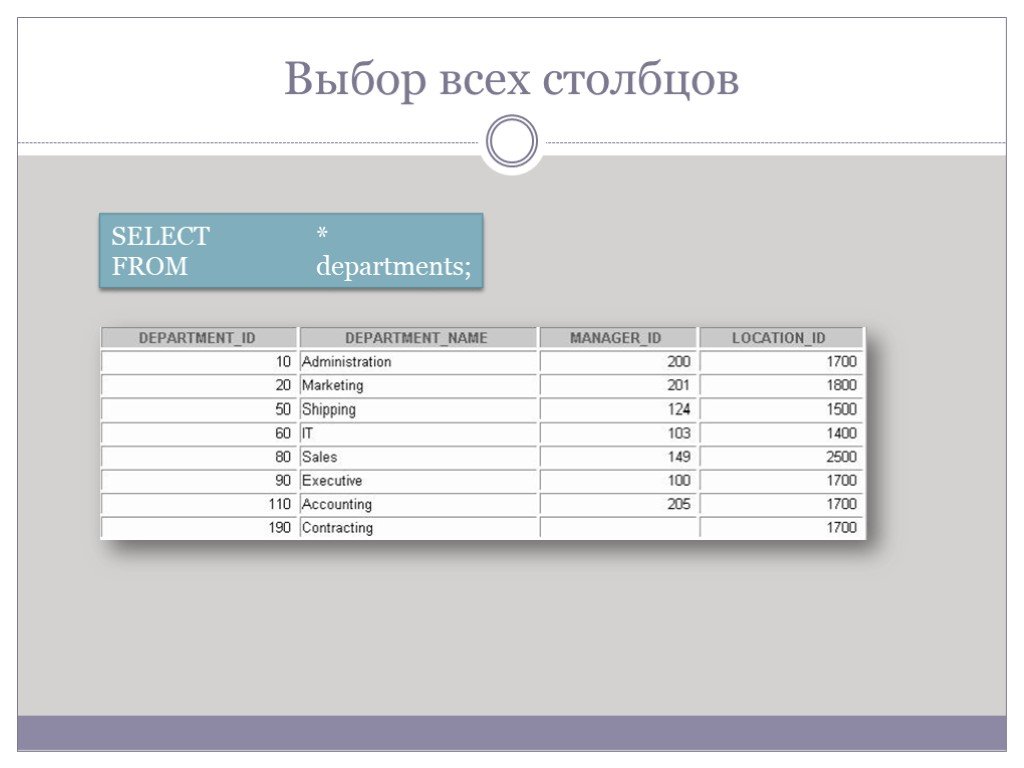 Слайд 28
Слайд 28 Слайд 29
Слайд 29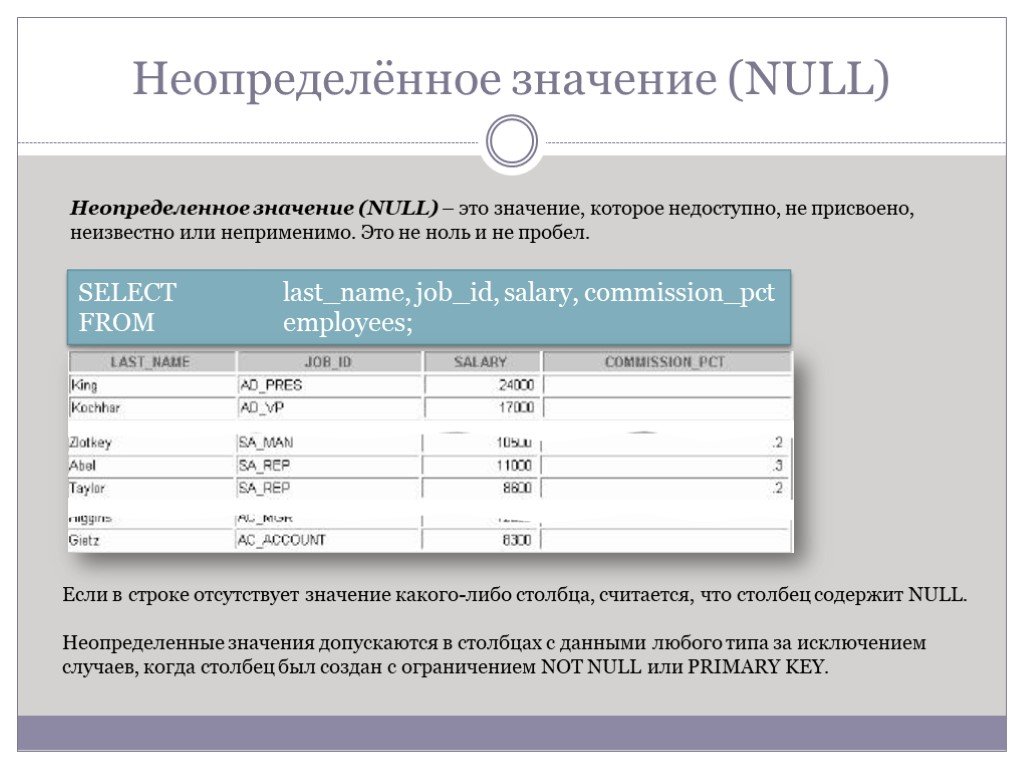 Слайд 30
Слайд 30 Слайд 31
Слайд 31 Слайд 32
Слайд 32 Слайд 33
Слайд 33 Слайд 34
Слайд 34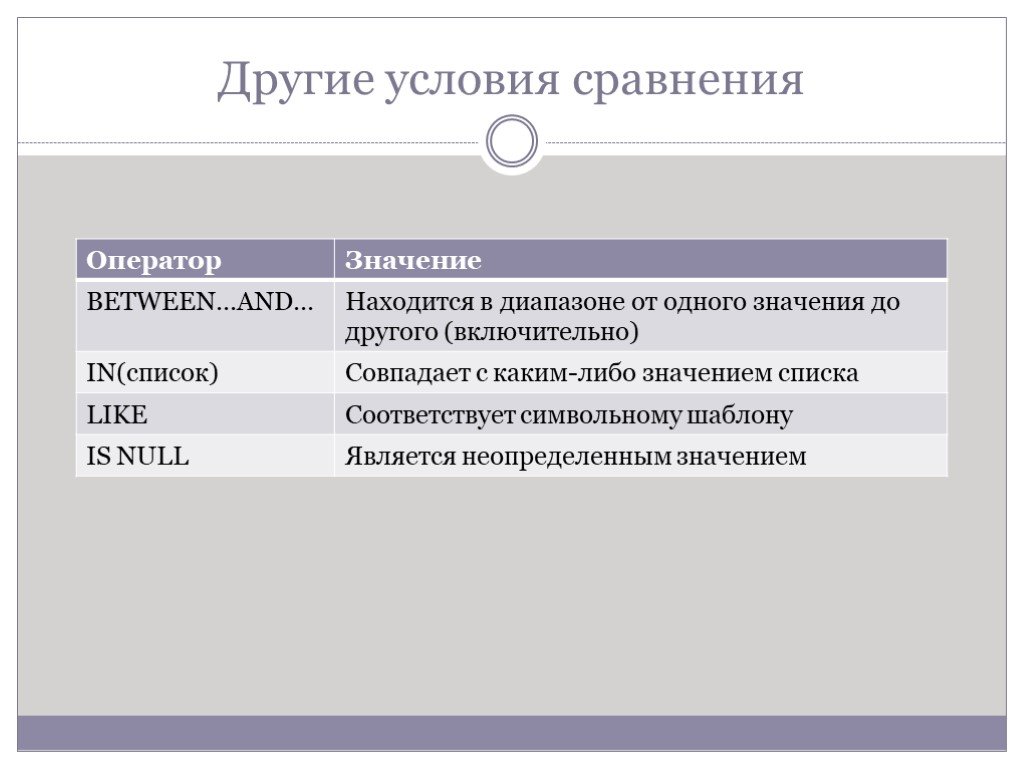 Слайд 35
Слайд 35 Слайд 36
Слайд 36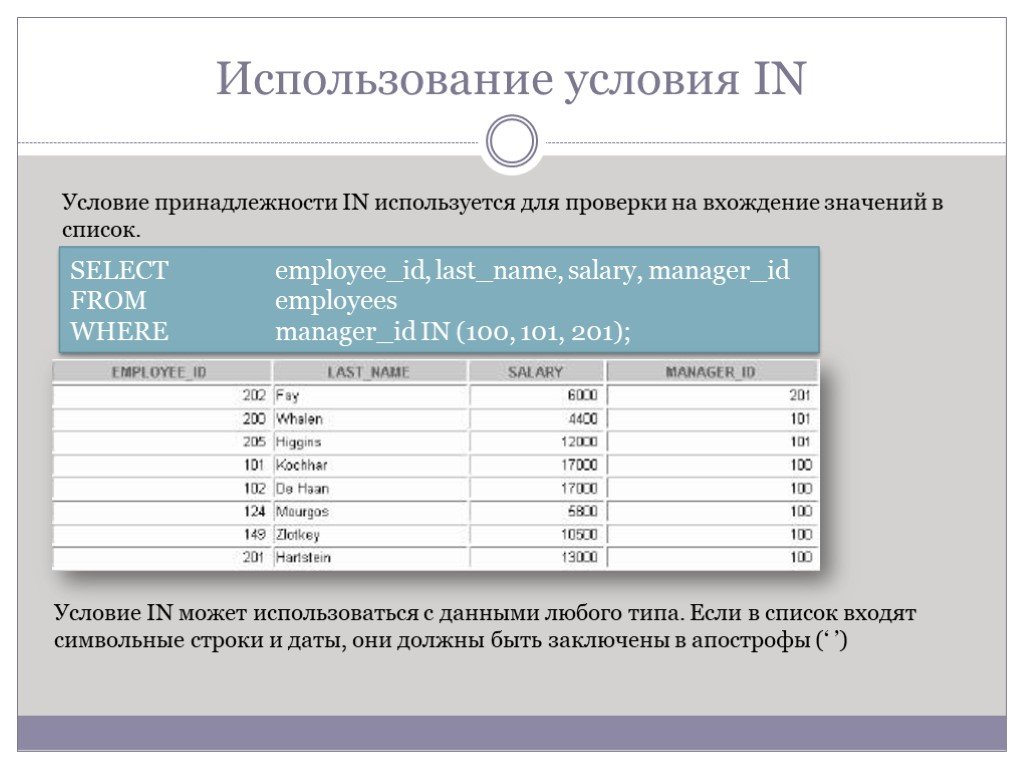 Слайд 37
Слайд 37 Слайд 38
Слайд 38 Слайд 39
Слайд 39 Слайд 40
Слайд 40 Слайд 41
Слайд 41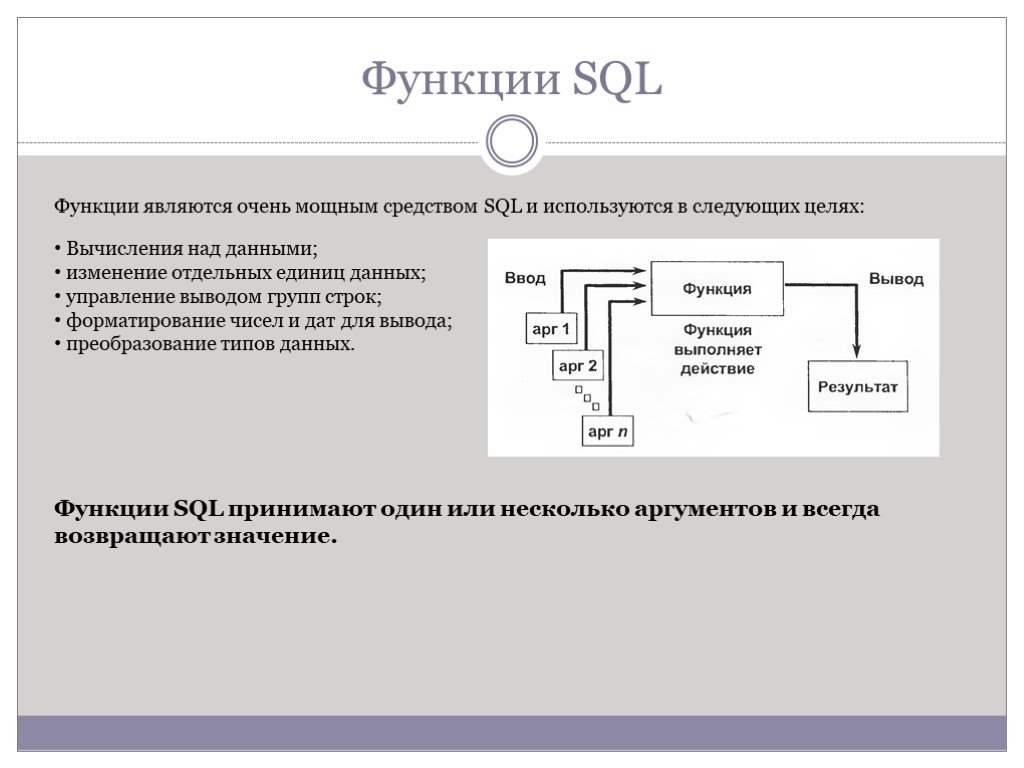 Слайд 42
Слайд 42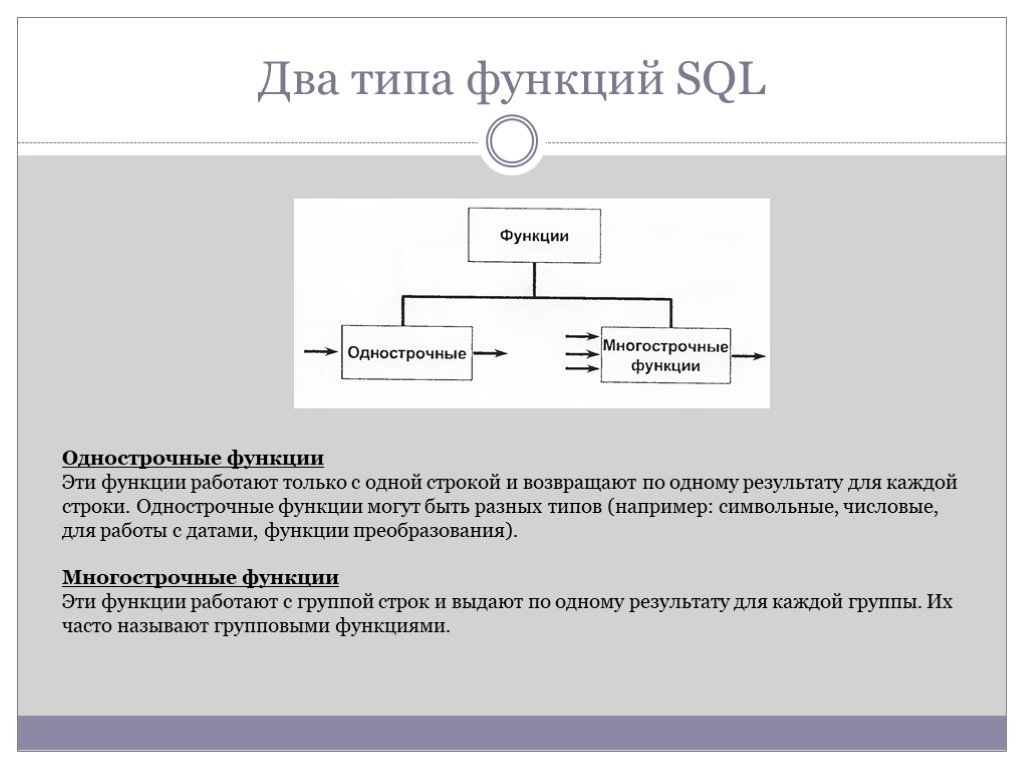 Слайд 43
Слайд 43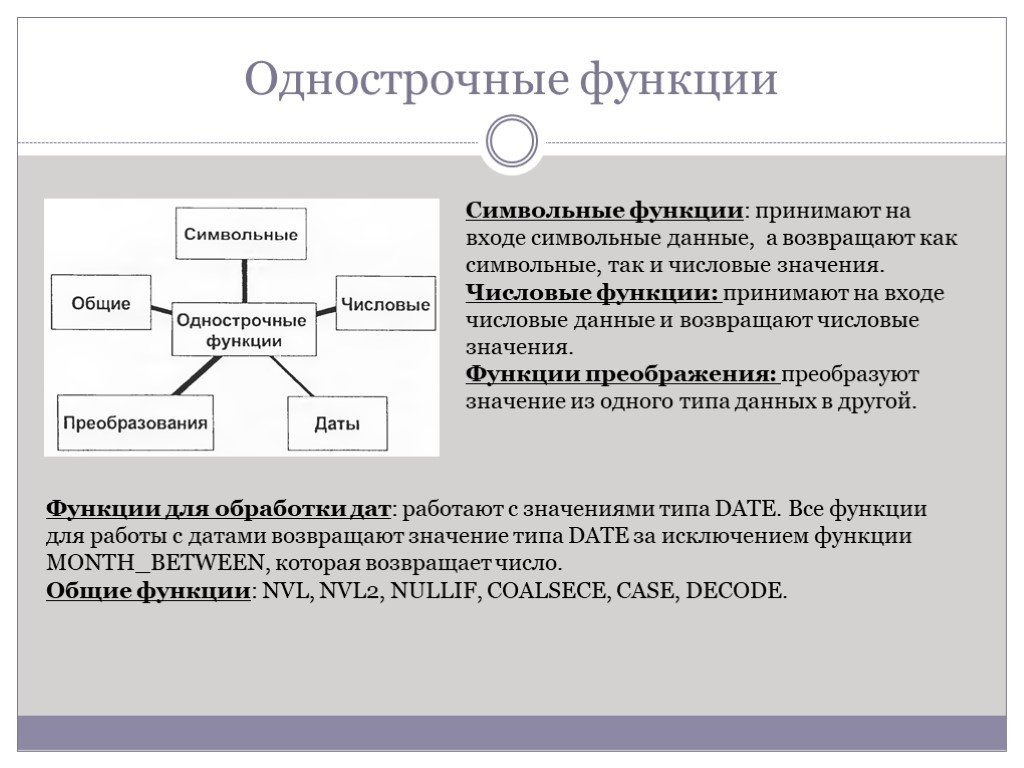 Слайд 44
Слайд 44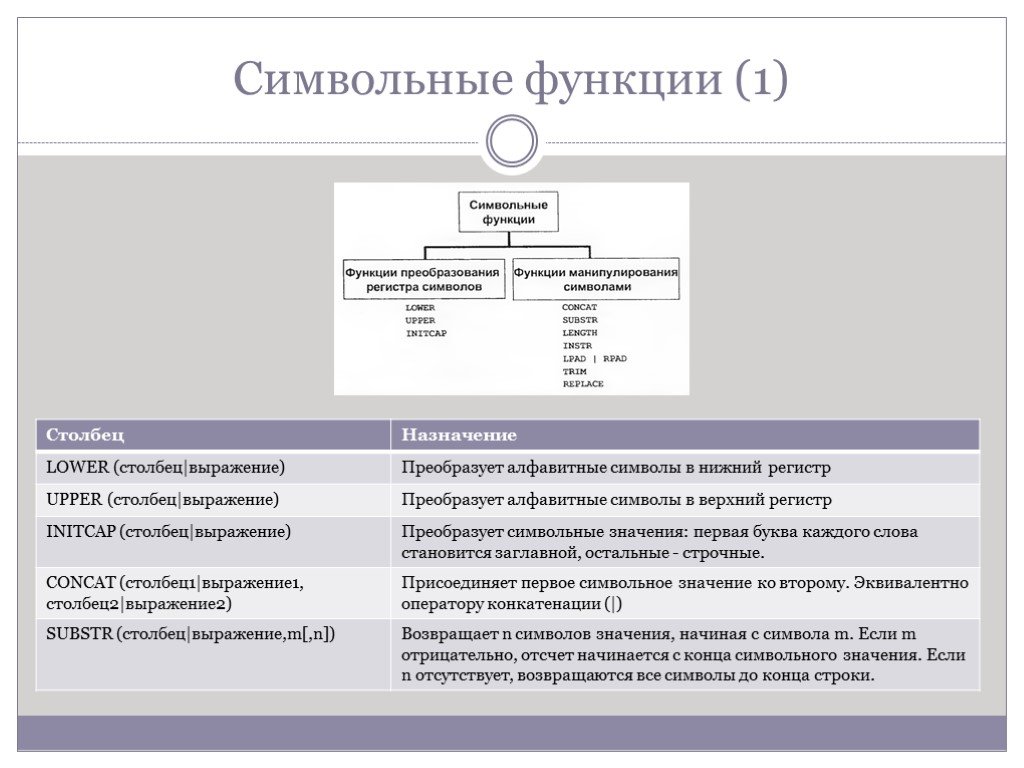 Слайд 45
Слайд 45 Слайд 46
Слайд 46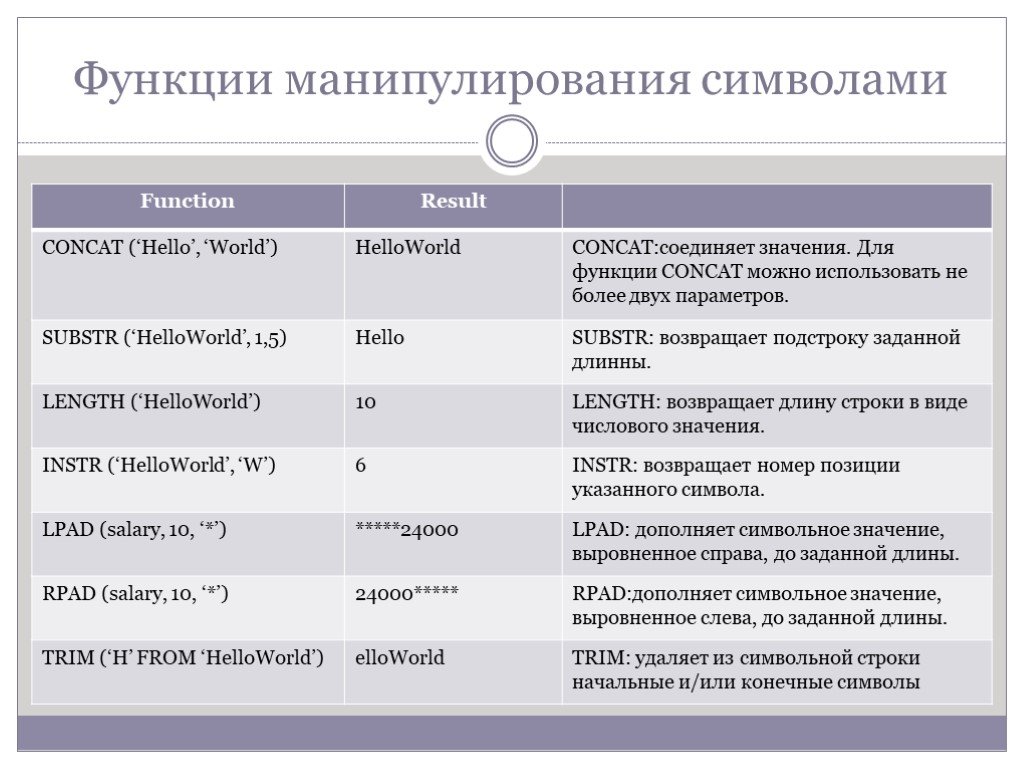 Слайд 47
Слайд 47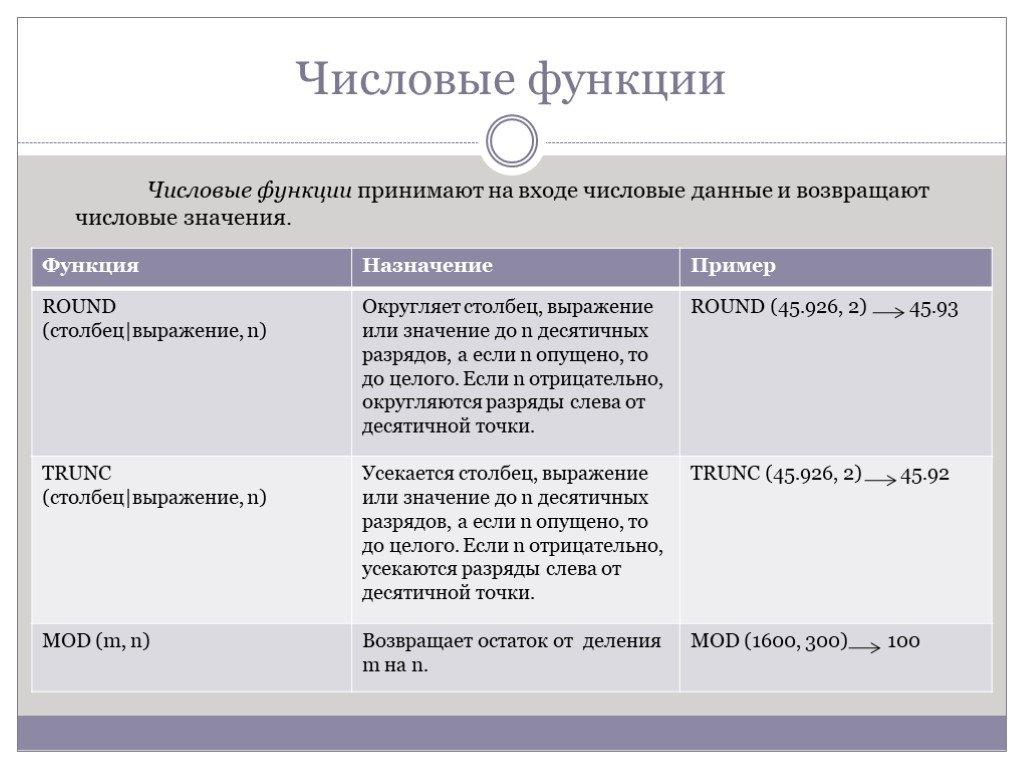 Слайд 48
Слайд 48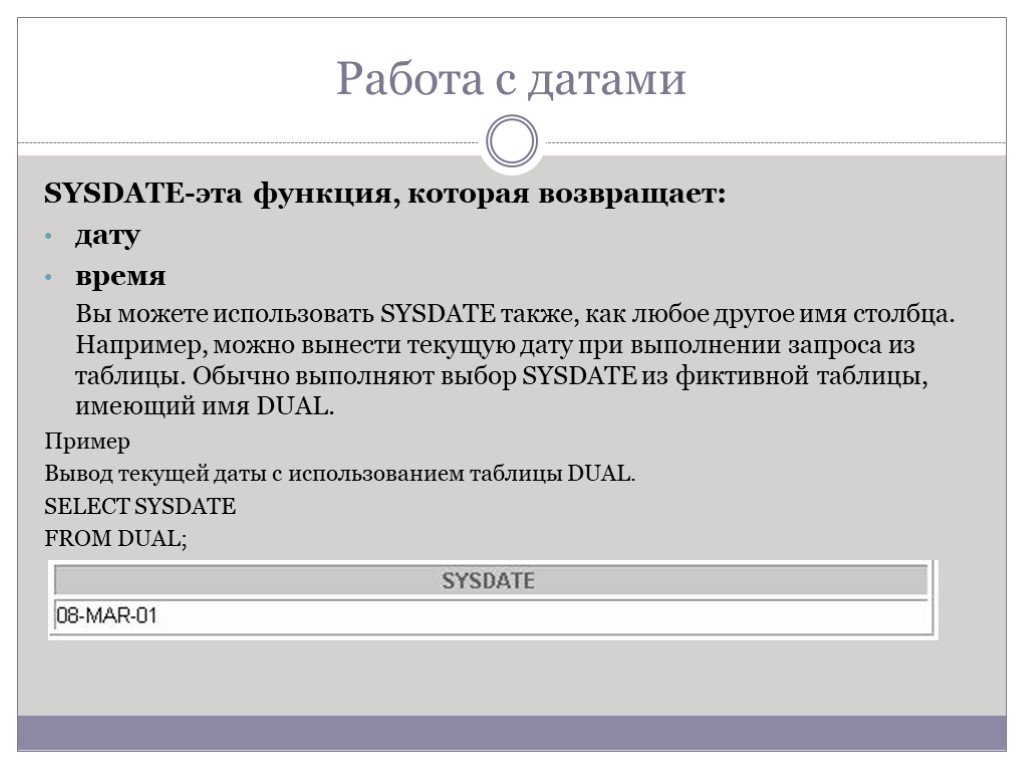 Слайд 49
Слайд 49 Слайд 50
Слайд 50 Слайд 51
Слайд 51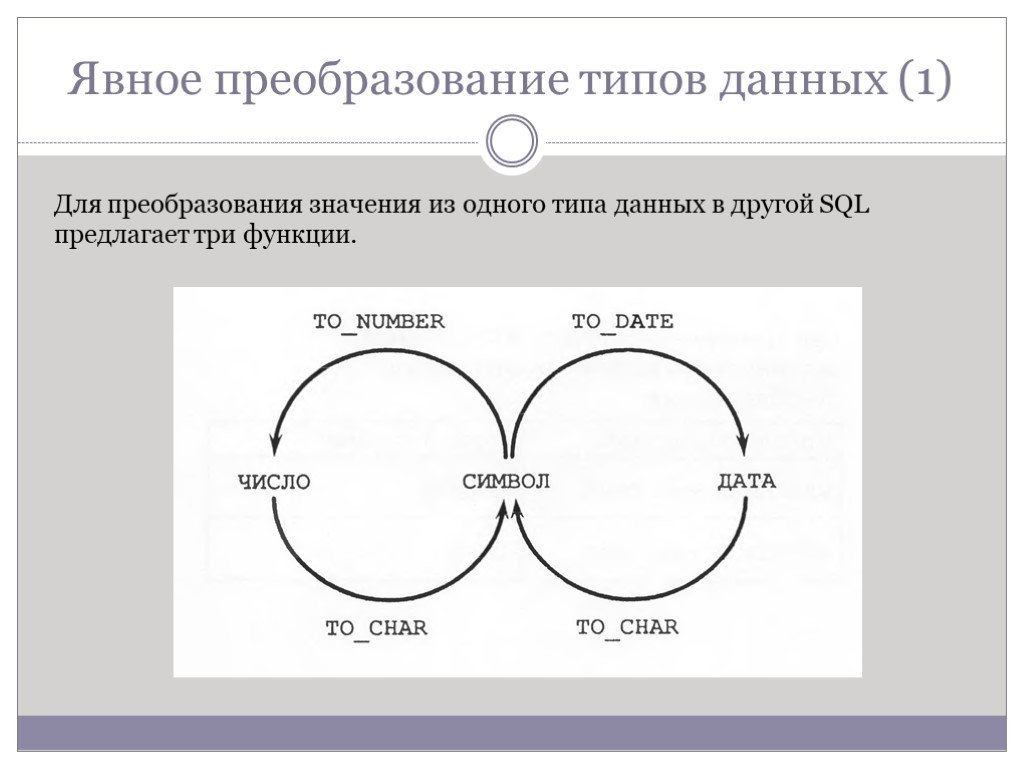 Слайд 52
Слайд 52 Слайд 53
Слайд 53 Слайд 54
Слайд 54 Слайд 55
Слайд 55 Слайд 56
Слайд 56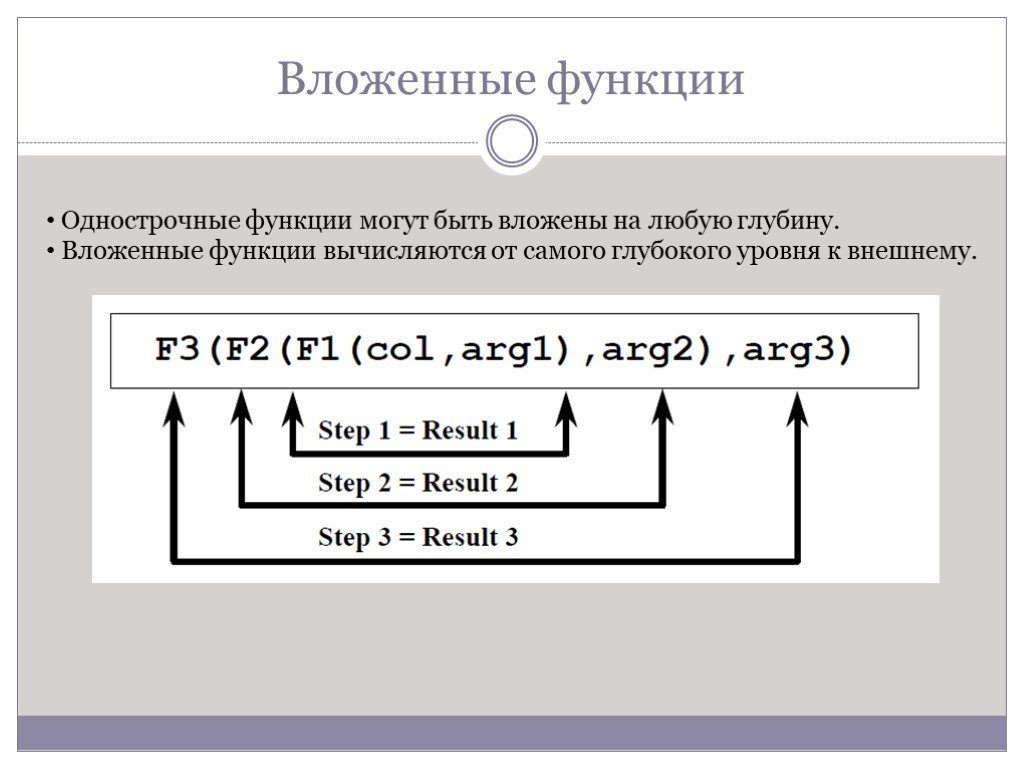 Слайд 57
Слайд 57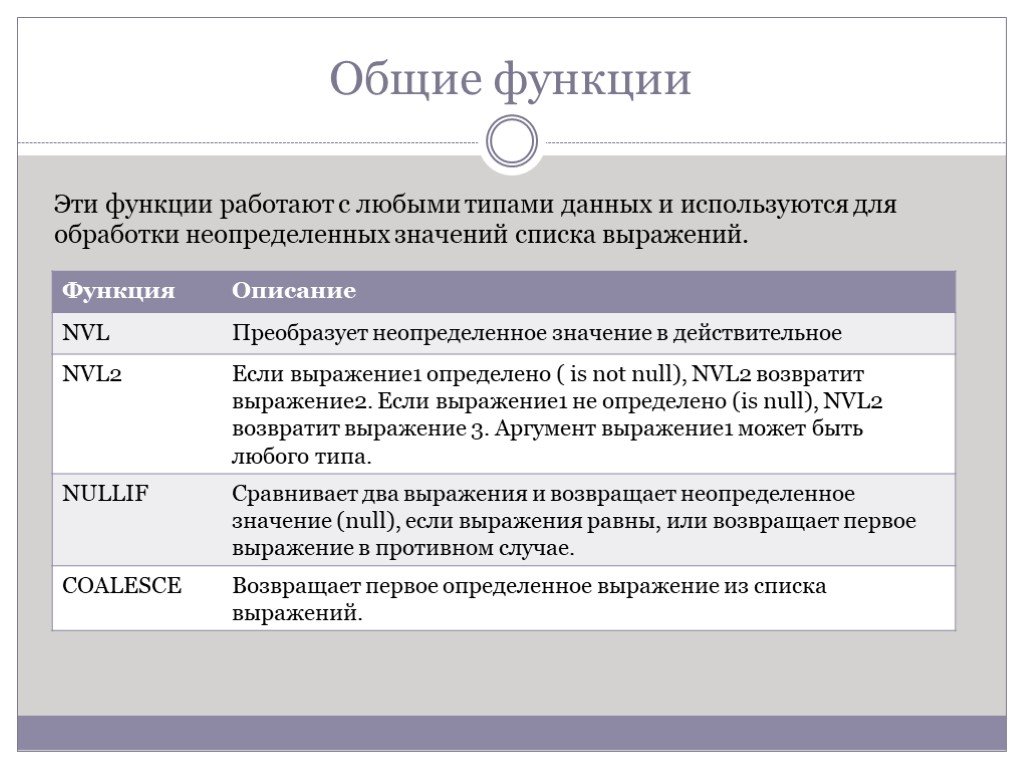 Слайд 58
Слайд 58 Слайд 59
Слайд 59 Слайд 60
Слайд 60 Слайд 61
Слайд 61 Слайд 62
Слайд 62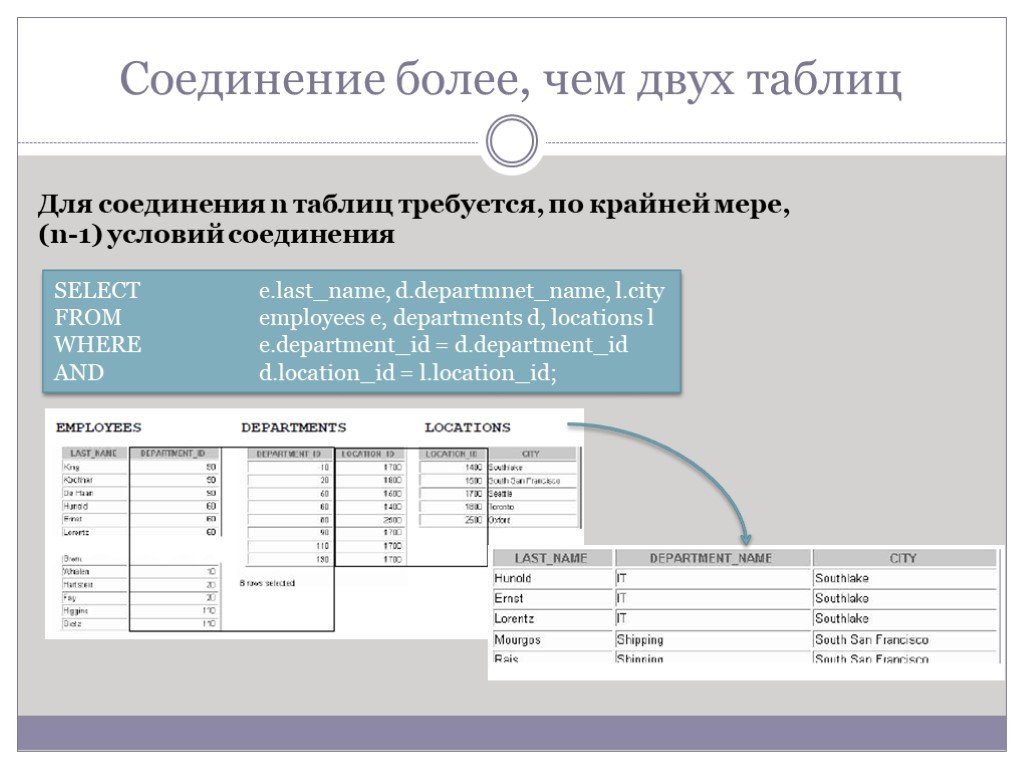 Слайд 63
Слайд 63 Слайд 64
Слайд 64 Слайд 65
Слайд 65 Слайд 66
Слайд 66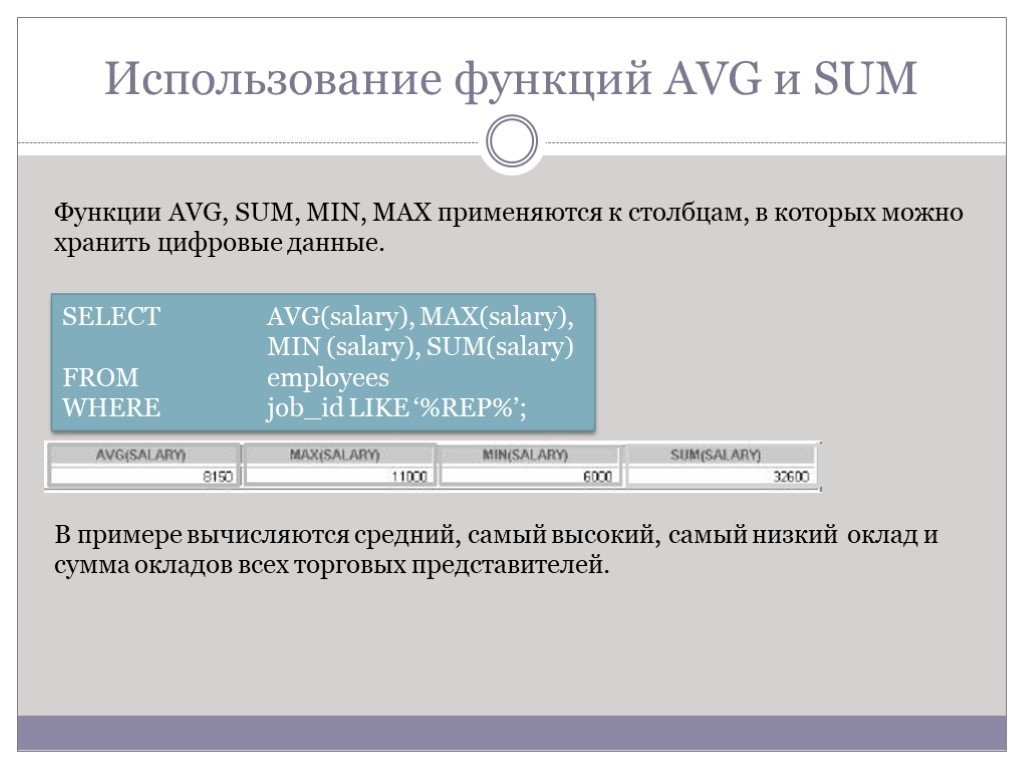 Слайд 67
Слайд 67 Слайд 68
Слайд 68 Слайд 69
Слайд 69 Слайд 70
Слайд 70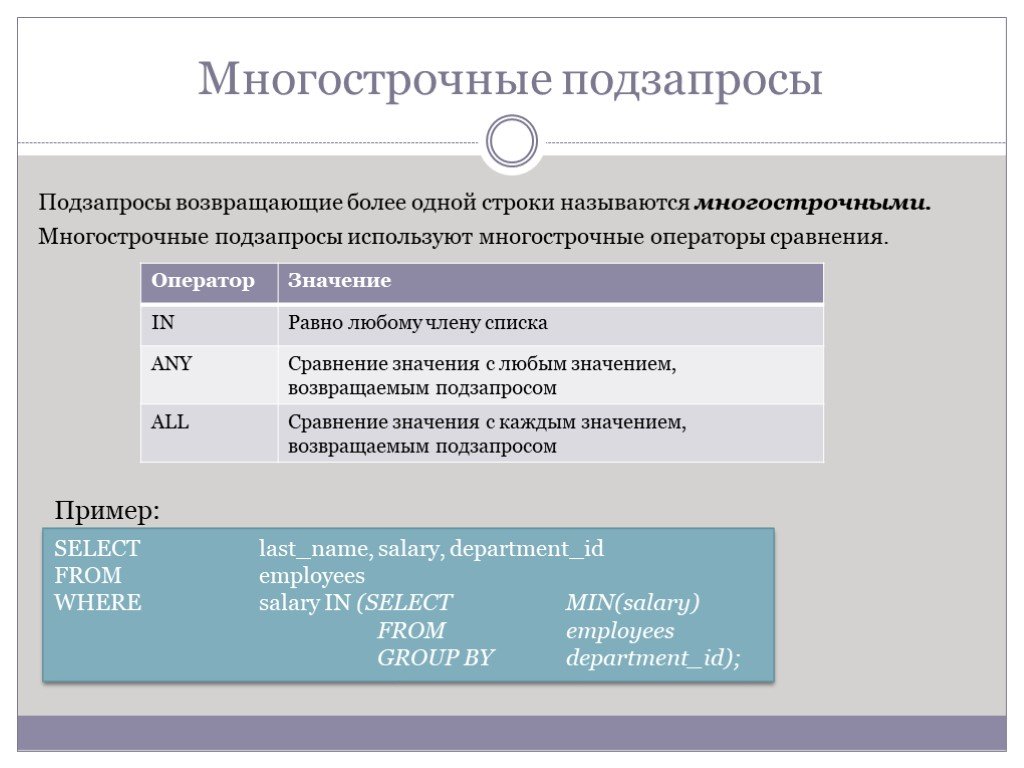 Слайд 71
Слайд 71 Слайд 72
Слайд 72 Слайд 73
Слайд 73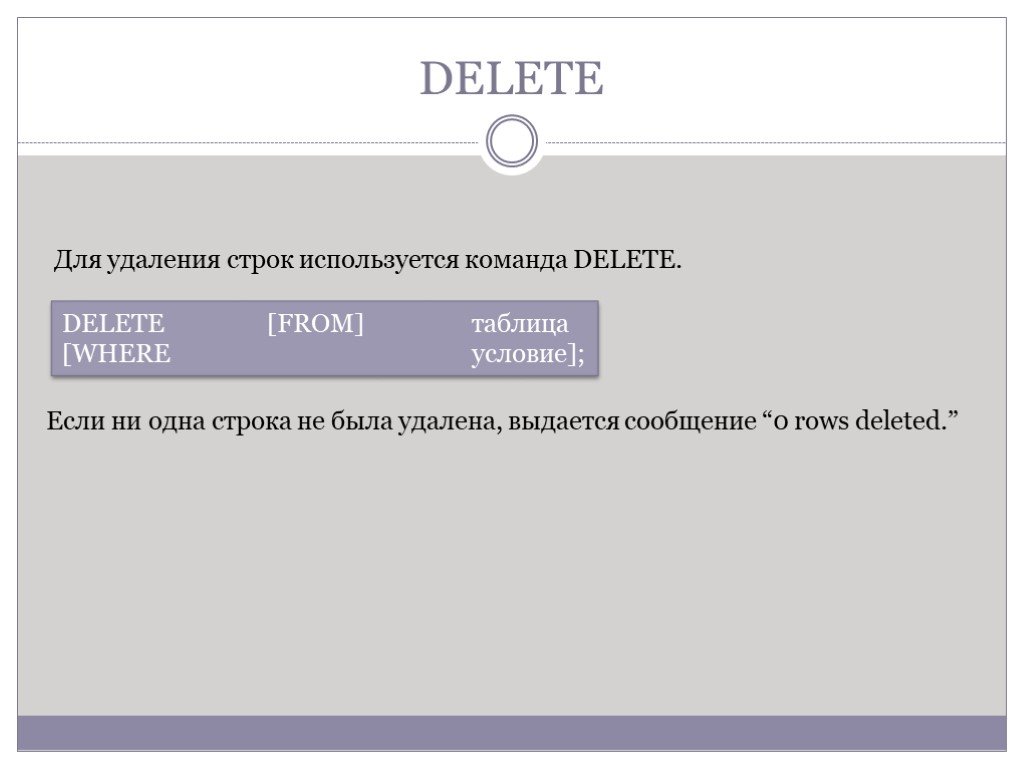 Слайд 74
Слайд 74 Слайд 75
Слайд 75 Слайд 76
Слайд 76 Слайд 77
Слайд 77 Слайд 78
Слайд 78 Слайд 79
Слайд 79 Слайд 80
Слайд 80 Слайд 81
Слайд 81 Слайд 82
Слайд 82 Слайд 83
Слайд 83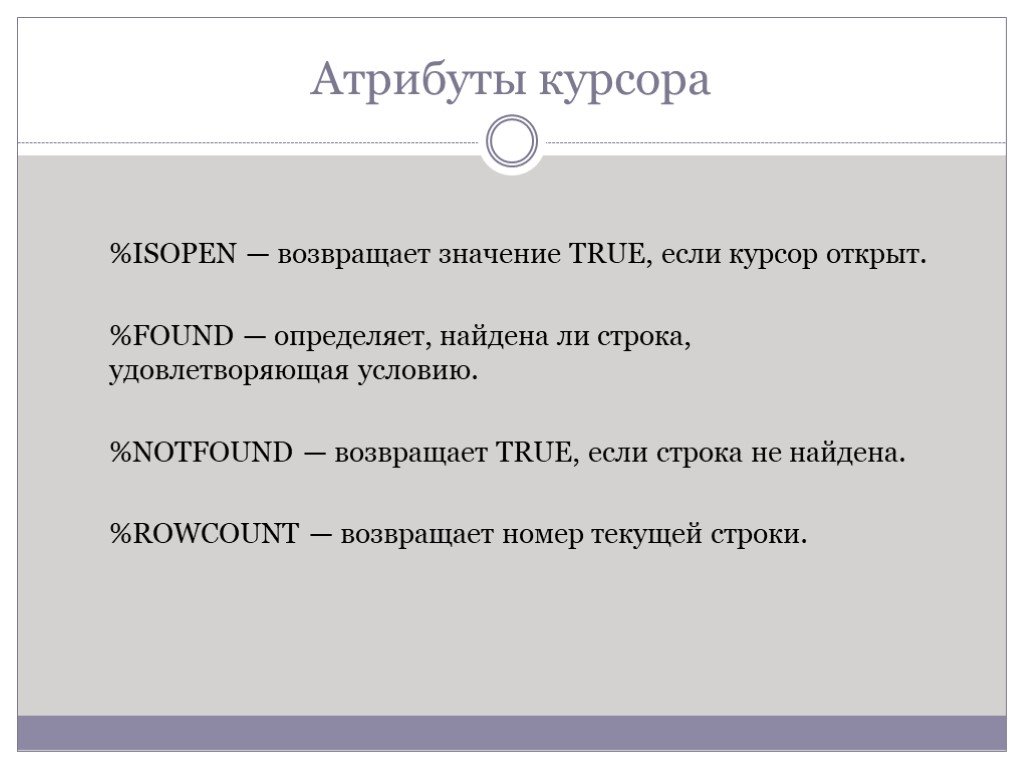 Слайд 84
Слайд 84 Слайд 85
Слайд 85 Слайд 86
Слайд 86 Слайд 87
Слайд 87 Слайд 88
Слайд 88 Слайд 89
Слайд 89 Слайд 90
Слайд 90








