

Слайд 2Психоакустика
Звук – аналоговое явление. Поэтому его адекватная обработка цифровыми методами представляет собой сложную проблему. Ее решение лежит в области психоакустики – науки, изучающей особенности восприятия звука человеком. Уяснив, как человек ощущает звук, можно попытаться смоделировать такие ощущения с помощью цифровых сигналов. Восприятие звука Звук представляет собой локальные изменения давления воздуха, происходящие с определенной частотой. Эти изменения воспринимаются органом слуха. Чем больше частота таких изменений, тем более высокий тон слышит человек. Диапазон звуковых частот, слышимых людьми, в общем случае считается лежащим в границах 20 – 20 000 Гц. Колебания более низкой частоты называют инфразвуком, они не слышны но могут быть болезненны и вызывать чувство тревоги. Колебания высокой частоты называют ультразвуком. Они тоже не слышны но воспринимаются многими животными. Наилучшее восприятие человеком звука лежит в диапазоне 450 – 4000 Гц (человеческий голос). Именно в этом диапазоне работает пространственна ориентация – определение местоположения источника звука. Звуки выше 4 кГц различаются только по частотам. Пространственное разрешение - низкое. Диапазон частот воспринимаемых конкретным человеком сильно зависит от его индивидуальных особенностей. Замечены резкие сужения диапазона после 25 лет и после 50 лет (верхняя граница сдвигается до 15-17 кГц). Однако музыканты, звукорежиссеры, композиторы часто избегаю такого спада благодаря опыту.

Слайд 3Человек очень редко находиться в таком окружении, чтобы был слышен только один источник звука. Обычно их множество, они расположены на разном расстоянии. В разных точках пространства. К тому же при отражении и поглощении звука различными предметами вносятся искажения в распространение звуковой волны. Происходит наложение звуковых колебаний друг на друга. Человеческие органы слуха стереофонические, то есть левое и правое ухо воспринимают сигнал независимо. Поэтому человек способен выделять определенный звуковой сигнал и определять направление на его источник. Сильное влияние на ориентировку оказывает окружающая обстановка. В условиях многократного отражения и поглощения звука (например в лесу) направление на источник определить трудно. Органы слуха человека воспринимают результирующую звуковую картину. Поступившие сигналы обрабатываются головным мозгом по индивидуальному алгоритму и интерпретируются в знакомые человеку понятия. Каков алгоритм обработки звука внутри мозга – до сих пор точно не известно

Слайд 4Человек способен воспринимать несколько различных параметров звука: громкость, частоту, пространственное положение источника, гармонические колебания. Громкость звука измеряется в децибелах, по логарифмической шкале, где за 0 принята минимальная громкость звука на частоте 3000 Гц еще различимая человеком (величина звукового давления 4мкПа). В цифровой обработке звука используют обратную шкалу – за 0 принято максимально возможное значение. Без болевых ощущений здоровый человек различает звуки громкостью до 120 дБ. При уровне около 150 дБ происходит повреждение органов слуха. Наиболее высока чувствительность к звукам в диапазоне 1 – 4 кГц. Для звука частотой 100 Гц порог слышимости 40 дБ (то есть с амплитудой в 100 раз больше чем при 3000 Гц). На частоте 10 кГц порог слышимости 210 дБ. Именно поэтому в колонках сабвуферы гораздо мощнее высокочастотные динамики.

Слайд 5Частота звука лучше всего различается в диапазоне 1 - 4 кГц – в среднем с шагом 0,3%. На более низких частотах шаг распознавания падает до 4%. Однако люди с музыкальным слухом гораздо более чувствительны к частотному спектру. У профессионалов шаг достигает 0,1%. Очень важная характеристика слуховой системы человека — способность различать два тона с разными частотами. Проверки показали, что в полосе от 0 до 16 кГц человеческий слух способен различать до 620 градаций частот (в зависимости от интенсивности звука), при этом примерно 140 градаций находятся в промежутке от 0 до 500 Гц. Пространственное разрешение буде рассмотрено отдельно Гармоники являются основными составляющими звука. Подавляющему числу людей приятны именно гармонические колебания. Такие звуки характерны для живой природы.
. Она заключается в том, что в ходе записи в течении каждой секунды многократно регистрируется амплитуда звуковой волны. Данное текущее значение амплитуды масштабирует")
Слайд 6Цифровая обработка звука Метод натуральной цифровой записи звука называется PCM (Pulse Code Modulation – импульсно-кодовая модуляция). Она заключается в том, что в ходе записи в течении каждой секунды многократно регистрируется амплитуда звуковой волны. Данное текущее значение амплитуды масштабируется относительно выбранного максимального и округляется до целого числа. На качество оцифровки сильно влияет частота с которой берутся амплитуды – частота дискретизации. И величина единичного массива данных – глубина оцифровки, разрядность. Записью хорошего качества считается запись с частотой дискретизации 44100 Гц и глубино оцифровки 16 бит (Audio CD). Повышение разрядности до 16 бит позволяет расширить охватываемый диапазон до -96 Дб. Однако сигналы с предельным уровнем сливаются с шумами дискретизации. Для определения соотношения сигнал/шум используют формулу SNR=Vsignal/Vnoise=6,02*N+C (дБ) Где N разрядность а -15

Слайд 7Пространственное звучание Человек слышит двумя ушами и поэтому способен различать направление прихода звуковых сигналов. Эту способность слуховой системы человека называют би-науральным эффектом. Механизм распознавания направления прихода звуков сложен, и надо сказать, что в его изучении и способах применения еще не поставлена точка. Уши человека расположены на расстоянии друг от друга (по ширине головы). Скорость распространения звуковой волны невелика. Сигнал, приходящий от источника звука, находящегося напротив слушателя, приходит в оба уха одновременно, и мозг интерпретирует это как расположение источника сигнала либо позади, либо спереди, но не сбоку. Если же сигнал приходит от источника, смещенного относительно центра головы, то звук приходит в одно ухо раньше, чем во второе, что позволяет мозгу интерпретировать это как приход сигнала слева или справа и даже приблизительно определить угол прихода. Численно разница во времени прихода сигнала в левое и правое ухо, составляющая от 0 до 1 мс, смещает мнимый источник звука в сторону того уха, которое воспринимает сигнал раньше. Такой способ определения направления прихода звука используется мозгом в полосе частот от 300 Гц до 1 кГц. Направление прихода звука для частот выше 1 кГц определяется мозгом человека путем анализа громкости звука. Дело в том, что звуковые волны с частотой выше 1 кГц быстро затухают в воздушном пространстве. Поэтому интенсивность звуковых волн, доходящих до левого и правого ушей слушателя, отличаются, что позволяет мозгу определять направление прихода сигнала по разнице амплитуд. Если звук в одном ухе слышен лучше, чем в другом, следовательно, источник звука находится со стороны того уха, в котором он слышен лучше. Подспорьем в определении направления прихода звука является способность человека повернуть голову в сторону кажущегося источника звука, чтобы проверить верность определения. Способность мозга определять направление прихода звука по разнице во времени прихода сигнала в левое и правое ухо, а также путем анализа громкости сигнала используется в стереофонии. Имея всего два источника звука, можно создать у слушателя ощущение наличия мнимого источника зву ка между двумя физическими. Причем этот мнимый источник можно «расположить» в любой точке на линии, соединяющей два физических источника. Для этого нужно воспроизвести одну аудиозапись (например, со звуком рояля) через оба физических источника, но сделать это с некоторой временной задержкой в одном из них и соответствующей разницей в громкости. Грамотно используя описанный эффект, можно при помощи двухканальной аудиозаписи донести до слушателя почти такую картину звучания, какую он ощутил бы сам, лично присутствуя, например, на каком-нибудь концерте. Такую двухканальную запись называют стереофонической. Одноканальная же запись называется монофонической. На самом деле для качественного донесения до слушателя реалистичного пространственного звучания обычной стереофонической записи не всегда достаточно. Основная причина этого кроется в том, что стереосигнал, приходящий к слушателю от двух физических источников звука, определяет расположение мнимых источников лишь в той плоскости, в которой расположены реальные физические источники звука. Естественно, «окружить слушателя звуком» при этом не удается. По той же причине заблуждением является и мысль о том, что объемное звучание обеспечивается квадрофониче-ской (четырехканальной) системой (два источника перед слушателем и два позади него). В целом путем выполнения многоканальной записи нам удается лишь донести до слушателя тот звук, каким он был «услышан» расставленной нами звуковоспринимающей аппаратурой (микрофонами). Для воссоздания же более или менее реалистичного, действительно объемного звучания прибегают к принципиально другим подходам, в основе которых лежат более сложные приемы, моделирующие особенности слуховой системы человека, а также физические особенности и эффекты передачи звуковых сигналов в пространстве.

Слайд 8Имея всего два источника звука, можно создать у слушателя ощущение наличия мнимого источника зву ка между двумя физическими. Причем этот мнимый источник можно «расположить» в любой точке на линии, соединяющей два физических источника. Для этого нужно воспроизвести одну аудиозапись (например, со звуком рояля) через оба физических источника, но сделать это с некоторой временной задержкой в одном из них и соответствующей разницей в громкости. Грамотно используя описанный эффект, можно при помощи двухканальной аудиозаписи донести до слушателя почти такую картину звучания, какую он ощутил бы сам, лично присутствуя, например, на каком-нибудь концерте. Такую двухканальную запись называют стереофонической. Одноканальная же запись называется монофонической. На самом деле для качественного донесения до слушателя реалистичного пространственного звучания обычной стереофонической записи не всегда достаточно. Основная причина этого кроется в том, что стереосигнал, приходящий к слушателю от двух физических источников звука, определяет расположение мнимых источников лишь в той плоскости, в которой расположены реальные физические источники звука. Естественно, «окружить слушателя звуком» при этом не удается. По той же причине заблуждением является и мысль о том, что объемное звучание обеспечивается квадрофониче-ской (четырехканальной) системой (два источника перед слушателем и два позади него). В целом путем выполнения многоканальной записи нам удается лишь донести до слушателя тот звук, каким он был «услышан» расставленной нами звуковоспринимающей аппаратурой (микрофонами). Для воссоздания же более или менее реалистичного, действительно объемного звучания прибегают к принципиально другим подходам, в основе которых лежат более сложные приемы, моделирующие особенности слуховой системы человека, а также физические особенности и эффекты передачи звуковых сигналов в пространстве. Один из таких инструментов — использование функций HRTF (Head Related Transfer Function). Этот метод (по сути — библиотеки функций) позволяет специальным образом преобразовать звуковой сигнал и обеспечить достаточно реалистичное объемное звучание, рассчитанное на прослушивание даже в наушниках.
 или специальное «цифровое ухо». В его уши")
Слайд 9Суть HRTF — накопление библиотеки функций, описывающих психофизическую модель восприятия объемности звучания слуховой системой человека. Для создания библиотек HRTF используется искусственный манекен KEMAR (Knowles Electronics Manikin for Auditory Research) или специальное «цифровое ухо». В его уши встраиваются микрофоны, с помощью которых осуществляется запись. Звук воспроизводится источниками, расположенными вокруг манекена. В результате запись от каждого микрофона представляет собой звук, «прослушанный» соответствующим ухом манекена с учетом всех изменений, которые звук претерпел на пути к уху (затухания и искажения как следствия огибания головы и отражения от разных ее частей). Расчет функций HRTF производится с учетом исходного звука и звука, «услышанного» манекеном. Собственно, сами опыты состоят в воспроизведении разных тестовых и реальных звуковых сигналов, их записи с помощью манекена и дальнейшего анализа. Накопленная таким образом база функций позволяет затем обрабатывать любой звук так, что при его воспроизведении через наушники у слушателя создается впечатление, будто звук исходит не из наушников, а откуда-то из окружающего его пространства. Таким образом, HRTF представляет собой набор трансформаций, которые претерпевает звуковой сигнал на пути от источника звука к слуховой системе человека. Рассчитанные однажды опытным путем HRTF могут быть применены для обработки звуковых сигналов с целью имитации реальных изменений звука на его пути от источника к слушателю. HRTF имеет, конечно, и недостатки, однако в целом идея использования HRTF вполне удачна. Реализация HRTF в том или ином виде лежит в основе ряда современных технологий пространственного звучания, таких, как QSound 3D (Q3D), ЕАХ, Aureal3D (A3D) и др. Записи сделанные с использованием HRTF называются binaural recording и стоят дороже обычных

Слайд 11зависимость задержки сигнала от положения источника
, которую Microsoft сделала доступной для разработчиков. Ядром DS3D является алгоритм 3D звучания, с помощью которого производится позиционирование звука а также встроенные технологии обработки акусти")
Слайд 12Цифровое моделирование трехмерного звука Direct Sound 3D Это основная инфраструктура (помимо A3D2.0), которую Microsoft сделала доступной для разработчиков. Ядром DS3D является алгоритм 3D звучания, с помощью которого производится позиционирование звука а также встроенные технологии обработки акустической информации в соответствии с параметрами окружения. Т.е. DS3D отвечает, в основном за позиционирование источника звука. В нынешних версиях (в DirectX 7/8/9) DirectSound3D, доступна такая новая функция, как искусственное эхо и другие характеристики. Звуковая картина в DirectSound3D создается довольно-таки просто. Каждому источнику звука в игре присваивается набор таких характеристик: исходная громкость, радиусы ближней и дальней зоны. Значение этих параметров проще всего пояснить на примере. Пусть исходная громкость объекта равна 100, радиус ближней зоны -- 5 метров, радиус дальней зоны -- 50 метров. Тогда, если расстояние между источником и слушателем составляет от 0 до 5 метров, громкость будет оставаться равной 100. На расстояниях от 5 до 50 метров громкость будет уменьшаться пропорционально 1/Rn (обычно n=1). И, наконец, после 50 метров громкость перестанет уменьшаться и будет оставаться постоянной На основе информации о координатах и скоростях источников звука относительно слушателя формируется трехмерный звуковая картина. Координаты нужны для позиционирования и определения громкости объектов, а скорости используются для учета эффекта Доплера. Если звуковая карта не поддерживает аппаратную акселерацию трехмерного звука, DirectSound3D может произвести реэндеринг при помощи встроенного программного движка -- DirectSound3D HEL (Hardware Emulation Level), однако HEL обеспечивает только минимальны набор функций (никакой трехмерности практически не ощущается) и при этом потребляет огромное количество ресурсов CPU.
 Разработанная и продвигаемая фирмой Creative Labs система пространственной обработки звука Environmental Audio eXtensions™ (EAX) используется многими разработчиками игр для создания естественного объемного звука с учетом специфики того помещения или пространства,")
Слайд 13Environmental Audio Extension (EAX) Разработанная и продвигаемая фирмой Creative Labs система пространственной обработки звука Environmental Audio eXtensions™ (EAX) используется многими разработчиками игр для создания естественного объемного звука с учетом специфики того помещения или пространства, где развиваются события игры и где находятся источники звуков. EAX можно представить как набор спецификаций, определяющих модели и алгоритмы для создания звуковых эффектов окружающего пространства или помещения, основанных на реверберации (Environmental Audio означает пространственный звук). Под понятием «реверберация» (от ср .-век. лат. reverberatio - отражение) понимают послезвучание, сохраняющееся после выключения источника звука и обусловленное неодновременным приходом в данную точку отраженных или рассеянных звуковых волн. Реверберация оказывает значительное влияние на слышимость речи и музыки в помещении. EAX также включает в себя набор функций API, позволяющих программисту воспользоваться аппаратной поддержкой EAX. EAX API является расширением базовой системы создания объемного звука DirectSound3D. Во время работы EAX приложения процесс обработки звука разделяется: DirectSound3D управляет местоположением, скоростью движения в 3D пространстве источников звука и слушателя, а EAX вносит в звук такие изменения, которые характеризуют окружающее источник звука пространство.
. Разумеется, что в первую очередь такая поддержка реализована на платах Creative. В основу EAX положена технология E-mu Environmental Modeling, поддерживаемая аудиопроцесс")
Слайд 14Поддержка системы EAX обеспечивается на аппаратном уровне встроенными аудиопроцессорами звуковых плат (звуковыми акселераторами). Разумеется, что в первую очередь такая поддержка реализована на платах Creative. В основу EAX положена технология E-mu Environmental Modeling, поддерживаемая аудиопроцессором EMU10K1, установленном на серии звуковых карт SBLive! В моделях EAX учитывается тип звукоизлучателей: наушники, стерео- и квадросистема. Аудиоакселератор EMU10K1 раскладывает любой звуковой поток на множество каналов, а потом на каждый канал в реальном времени накладывает реверберации. Благодаря чему создаются новые звуки, более близкие к их естественному звучанию в реальном пространстве. Так как человеческое ухо слышит не только звук, исходящий непосредственно от источника, но воспринимает и вторичные (и более поздние) звуковые колебания, которые определяются расстоянием до источника, а также параметрами реверберации, то именно дистанцию и реверберацию можно считать основными характеристиками пространства или помещения. Изначально предполагалось, что EAX не будет использовать геометрическую модель сцены, то есть источники звука могли быть не связаными с графическими объектами. Главное было создать звуковую атмосферу игровой сцены, то есть воздействовать на эмоциональное состояние игрока подобно тому, как в кинофильме звуковое сопровождение всегда подчеркивает остроту переживаний, акцентируясь на самом важном и пренебрегая незначительными звуковыми подробностями.

Слайд 15Руководствуясь этим подходом, создатели EAX в качестве основы выбрали статическую модель звуковой среды, а не ее геометрические параметры. В статической модели автоматически рассчитываются эффекты реверберации и отражения относительно слушателя с учетом размеров помещения, направления звука и других параметров, которые программист может устанавливать для каждого источника звука. Расчет статической модели требует меньших вычислительных ресурсов, чем моделей, основанных на геометрическом подходе. EAX использует подготовленные заранее звуковые модели, которые представляют собой набор числовых значений параметров помещения или пространства. Параметры эти характеризуют не расположение предметов в помещении, как это бывает в геометрической модели, а поведение звуковых волн в таком помещении или пространстве, то есть задержки распространения, степень затухания, звукопоглощение и звукоотражение на разных звуковых частотах. Если по сюжету игры необходимо сменить длинный коридор на большой ангар, то достаточно сменить одну статическую модель (модель коридора) на другую (модель ангара). EAX 1.0 Поддерживает изменение места реверберации и отражений; имеет большое количество пресетов; позволяет (с некоторыми ограничениями) изменять реверберационные параметры помещения; автоматически менять интенсивность реверберации, в зависимости от положения источника звука. EAX 1.0 строит звуковую сцену на основе заранее созданных пресетов, учитывая дистанцию между источниками звука и слушателем. EAX 2.0 Обновлена реверберационная модель; добавлены эффекты звуковых преград (Occlusions) и препятствий (Obstructions); реализовано отдельное управление ранними и поздними отражениями; возможен продолжительный контроль размеров помещений; учитываются акустические свойства воздуха (поглощение звука).

Слайд 16EAX 3.0 позволяет осуществить контроль за началом реверберации и ранними отражениями для каждого источника звука; реализует динамический переход между моделями пространства; содержит улучшенную дистанционную модель для автоматического управления реверберацией и начальными отражениями в зависимости от положения источников звука относительно слушателя. В этой спецификации уже происходит некоторый отход от статической модели и в ее состав включены методы, свойственные для геометрических моделей: Расчеты Ray-Tracing (отражение лучей) для получения параметров отражения для каждого источника звука. Кроме того, реализованы отдельные отражения для дальних эхо. Улучшенное дистанционное представление, призванное заменить статические реверберационные модели.
Creative Audigy2 ZS Platinum Pro (с внешним блоком) 7.1, Fireware, EAX4.0 Advanced HD, ASIO 2.0, OpenAL

Слайд 17Aureal 3D A3D стал первым API, поддерживающим аппаратную акселерацию трехмерного звука. A3D 1.х по своим возможностям примерно соответствует DirectSound3D. Однако у него есть несколько интересных особенностей, например улучшенная дистанционная модель, которая позволяет более реалистично описывать распространение звука в различных средах (чаще всего -- в воде или густом тумане). Но наиболее интересной особенностью A3D 1.х является Менеджер Ресурсов, который управляет 3D-потоками, воспроизводимыми в игре. И если количество потоков очень большое то Менеджер Ресурсов решает, какие потоки наиболее важны для слушателя в данной ситуации и именно для них использует аппаратные возможности A3D звуковой карты. Остальные потоки могут воспроизводиться в режиме обыкновенного стерео или не воспроизводиться вовсе (если число аудио-потоков уж очень большое). A3D 1.х является "родным" API для карт на чипсетах Aureal Vortex 1 (AU8820) и Vortex Advatage (AU8810). Перечислю наиболее популярные карты на этих чипсетах: Diamond Sonic Impact S90, Turtle Beach Montego, Aztech PCI-338-A3D, Genius SoundMaker 64 и, конечно же, одноименные чипсетам OEM карты Aureal. Естественно, стандарт A3D 1.х поддерживают и карты на Vortex 2, но о них -- чуть позже. Поддержка A3D 1.х на уровне драйверов реализована во многих картах для которых "родными" API являются Sensaura и Q3D. Драйвера этих карт просто преобразовывают команды A3D в команды родных API. Как и в случае с трехмерной графикой, качество реализации таких "врапперов" бывает разным и зависит от конкретного производителя. Стоит упомянуть драйвер A2D от Aureal который реализует поддержку A3D через DirectSound3D. Названием A2D Aureal подчеркивает неполноценность этого драйвера. Действительно A2D реализует далеко не все функции A3D 1.х (не говоря уже о более поздних версиях A3D), однако с помощью этого драйвера можно получить неплохой трехмерный звук в играх с поддержкой A3D.

Слайд 18A3D 2.0 -- расширение стандарта A3D. Основной особенностью A3D 2.0 стала технология Wavetracing, которая позволяет существенно повысить реалистичность звуковой картины. В реальном мире мы слышим не только "прямые" звуки но и звуки претерпевшие отражения или прошедшие сквозь препятствия. Причем то, как звуки будут отражаться, искажаться при прохождении через препятствия и поглощаться зависит не только от геометрии окружающей среды, но и, например, от материала из которого изготовлены стены (напрашивается аналогия с полигонами и текстурами в трехмерной графике). Расчет Wavetracing происходит в реальном времени. То есть если изменилась геометрия окружающего пространства (игрок забежал за колонну или открылась дверь в другую комнату) -- тут же изменятся условия распространения звука. Естественно, что такой подход к расчету звуковой картины предъявляет очень большие требования к вычислительным ресурсам как звукового процессора так и CPU. Поэтому при включении A3D 2.0 количество FPS (кадров в секунду) падает довольно-таки существенно. При этом падение FPS намного больше, чем при использовании, скажем DirectSound3D+EAX (о сравнительных характеристиках разных API мы поговорим дальше). Однако стоит послушать как звучит A3D 2.0 в Unreal, Unreal Tournament или HalfLife, и вы сразу поймете, что FPS потрачены не зря! Технологию A3D 2.0 поддерживают только карты на чипсете Aureal Vortex 2 (AU8830). Перечислю наиболее популярные из них: Diamond Monster Sound MX300, Turtle Beach Montego II, Aureal SQ2200, Aureal SQ2500 (Super Quad Digital) и OEM карты Aureal Vortex 2. Нужно отметить, что Aureal SQ2500 основана на модифицированном варианте Vortex 2 и поэтому демонстрирует наилучшую производительность среди перечисленных звуковых карт.
. Sensaura3D совместима с DirectSound3D EAX 1.0, EAX 2.0, A3D 1.0 и понимает команды этих API. Таким образом, на картах")
Слайд 19Sensaura3D Sensaura, в отличии от Aureal или Creative, не производит собственных чипсетов или карт, а только лицензирует свои техологии сторонним производителям (Yamaha, ESS и др.). Sensaura3D совместима с DirectSound3D EAX 1.0, EAX 2.0, A3D 1.0 и понимает команды этих API. Таким образом, на картах с технологией Sensaura можно наслаждаться 3D-звуком не только в играх для данного API (игр с поддержкой Sensaura еще очень немного) но и в играх с поддержкой ранних версий EAX и A3D (а таковых сейчас подавляющее большинство). Хотя в этом случае нельзя гарантировать, что звук в таких играх будет таким же как для родных для EAX или A3D карт. Технология MacroFX используется для наиболее реалистичного позиционирования звука. Как и в DirectSound3D, в Sensaura3D окружающее пространство разбивается на зоны. Однако в отличие от DirectSound3D, MacroFX предусматривает разбиение на большее количество зон. Обратите внимание на зоны 3,4,5 на рисунке, которые не имеют аналогов в DirectSound3D. Наличие зон 3 и 4 позволяет моделировать такие эффекты как шепот в ухо или свист пуль, пролетающих в непосредственной близости от головы. Интересна также зона 5, которая предназначена для моделирования источников звуков, находящихся в голове

Слайд 20Технология ZoomFX предназначена для моделирования звука от крупных объектов, вроде проезжающего рядом поезда. В подавляющем большинстве API все источники звука представляются как точечные. Аналогичная ZoomFX технология есть только в A3D 3.0. Для создания реалистичного звука в помещениях используется технология EnvironmentFX которая по своим функциям во многом напоминает EAX. Однако, EnvironmentFX содержит ряд интересных особенностей (обработка ранних отражений, отражений от движущихся поверхностей, "растройка" звука и др.). Технология MultiDrive, предназначена для расширения "зоны трехмерности" звука Разработка под названием Digital Ear позволяет настроить параметры трехмерного звука под конкретного слушателя. При этом учитываются размеры головы, размеры ушей, глубина и тип ушной раковины. В общем, Sensaura обладает всеми необходимыми средствами для создания реалистичного трехмерного звука в играх. Жаль только, что разработчики игр пока не используют все возможности этой технологии. Звуковые чипсеты, поддерживающие Sensaura очень сильно сотличаются по своим характеристикам, поэтому нельзя сказать что при использовании Sensaura звук будет одинаковым на всех картах. Более того, те возможности Sensaura, которые на одних картах реализованы аппаратно, на других будут реализовываться при помощи CPU. Как яркий пример диаметрально разных по цене и возможностям чипсетов под Sensaura можно привести Maestro и Canyon3D (оба чипсета производства ESS). Если первый может аппаратно ускорять только 5 потоков трехмерного звука то второй -- 32 и к тому же обладает огромным количеством разных "наворотов". Именно на этом чипсете и построена новая карта от Diamond Multimedia -- Monster Sound MX400. Благодаря отличному соотношению цена/качество заслуженной популярностью пользуются карты на чипсете Yamaha 724 (Genius SoundMaker 128XG, Yamaha WaveForce 192D, и многочисленные ОЕМ карты одноименные чипсету). Сейчас на смену этому чипсету пришел новый -- Yamaha 744

Слайд 21QSound 3D QSound. Разработки этой компании использовались еще для Creative SB AWE64. Большинство технологий QSound не имеют отношения к позиционируемому звуку, однако и этой области компания добилась многого, создав технологию Q3D. Первая версия Q3D была предназначена для вывода звука на наушники или две колонки. В отличии от других технологий, использующих стандартные HRTF with cross-talk cancellation, Q3D использует собственную разработку, которая выгодно отличается малым потреблением вычислительных ресурсов. Q3D 2.0 уже может воспроизводить 3D-звук на четыре колонки и к тому же обладает многими современными технологиями для создания реалистичного звука, например QEM -- интерфейс для моделирования звуковых свойств окружающей среды, совместимый с EAX. Конечно у Q3D нет стольких наворотов, как например у A3D 3.0, EAX 3.0 или Sensaura, однако эта технология позволяет создавать довольно-таки приличный трехмерный звук, потребляя при этом очень немного вычислительных ресурсов. Среди новых чипсетов, поддерживающих Q3D 2.0 стоит упомянуть Trident 4DWAVE-DX и VLSI Thunderbird 128. Кстати на основе последнего сделана очень популярная у нас карта Aztech 368DSP. Interactive Active Sound Фирма EAR разработала технологию IAS для воспроизведения трехмерного звука в форматах EAX и A3D через 4 и более колонок. Технология независима от аппаратной части и прозрачна для API DirectSound3D и DirectMusic. Единый интерфейс обеспечивает воспроизведение трехмерного звука на любой системе

Слайд 22Подавляющее большинство новых игр, использующих трехмерный звук, поддерживает и A3D 1.0/2.0 и DirectSound3D+EAX 1.0/2.0, однако переключаться меду этими режимами как правило нельзя, даже если звуковая карта поддерживает и A3D и DirectSound3D+EAX. Обычно, если игра определят поддержку A3D 2.0 то ни а каких других API она и знать не хочет :-). Однако, как известно A3D 2.0 потребляет очень много вычислительных ресурсов и с этим API игра может заметно "тормозить". Приятным исключением является Half Life, в котором можно вручную выбрать EAX или A3D.

Слайд 23Устройство звуковой карты Рассмотрим устройство современной звуковой карты с разъемом PCI. На задней панели расположены разъемы ввода/вывода. Внешний сигнал может поступать на входы Line In, Mic In, Aux In, MIDI. На самой плате расположен разъем для подключения аудиовыхода CD-ROM Line In разъем типа мини-джек. Предназначен для подключения внешних источников звука: тюнеров, DVD/CD пллерови др. Чувствительность обычно составляет 0,1-0,3 В. Сигнал полностью проходит звуковой тракт Mic In микрофонный вход. Тип разъема – мини-джек. Используется для подключения микрофонов. Обладает чувствительностью 3-10 мВ. Сигнал обрабатывается предусилителем затем проходит через звуковой тракт Aux In (микшерный вход), обычно типа мини-джек. Используется для подключения внешнего источника сигнала, который нужно смешать с внутренним источником. Сигнал поступает на выходной микшер минуя звуковой тракт. MIDI служит для подключения джойстика или электронных музыкальных инструментов. Порт двунаправленный. Внутренний Aydio CD используется для подключения выходного аудиоканала CD-ROM. При этом сигнал минует усилитель CD-ROM и поступает в звуковой тракт на прямую. S/PDIF цифровой интерфейс для передачи звуковых сигналов в цифровой форме на внешние компоненты. Выходы звуковой платы обычно именуются Line Out сигнал выводиться без предусиления Speaker Out. сигнал выводиться с предусилением Все они подключаются через выходной микшер.

Слайд 24Микшеры входа-выхода обычно физически являются единым устройством осуществляющим коммутацию, нормализацию и смешение сигналов. Сигнал может поступать на микшер через усилитель или минуя его. Усилитель обычно имеет выходную мощность не более 4 Вт на канал и предпочтительнее использовать внешние усилители. Кодек отвечает за оцифровку звука и превращение цифрового звука в аналоговый сигнал. Все сигналы проходящие через звуковой тракт, за исключением S/PDIF проходят через кодек.
Слайд 25Звуковая карта может сама генерировать аудиосигнал. Для этого используют два метода. FM (частотная модуляция) Волновой табличный синтез (WTS) который работает на основе таблицы образцов звучания музыкальных инструментов и т.п. источников звука.
Слайд 26Аппаратные средства обработки звука Кодек AC’97
 Слайд 1
Слайд 1 Слайд 2
Слайд 2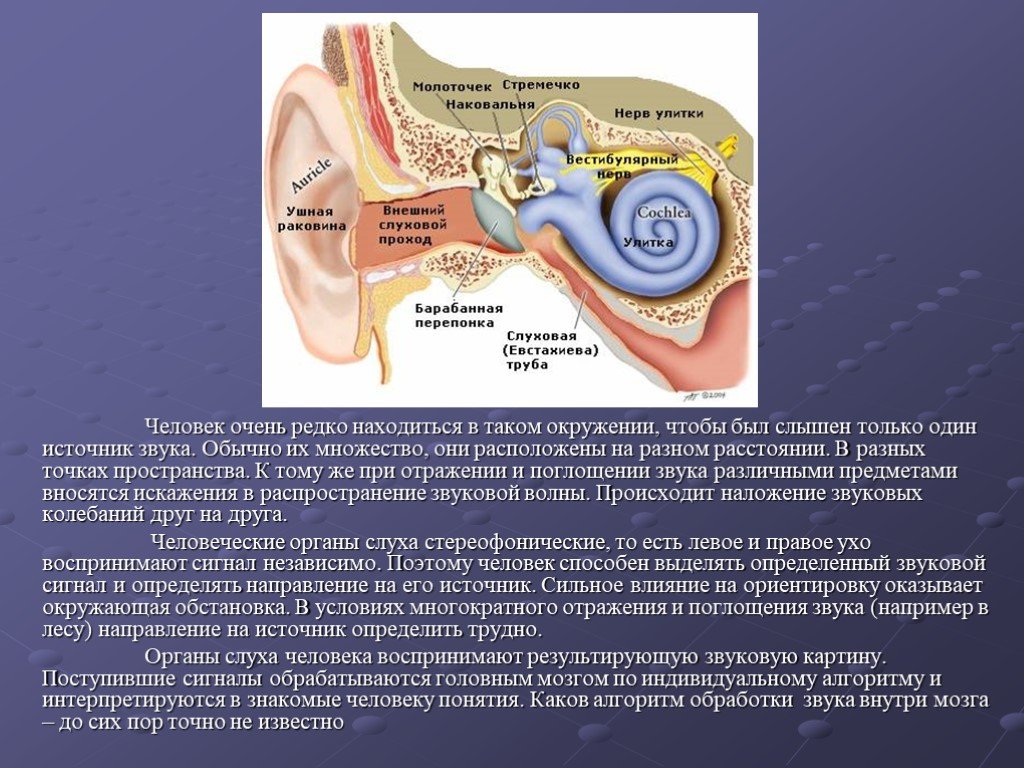 Слайд 3
Слайд 3 Слайд 4
Слайд 4 Слайд 5
Слайд 5 Слайд 6
Слайд 6 Слайд 7
Слайд 7 Слайд 8
Слайд 8 Слайд 9
Слайд 9 Слайд 10
Слайд 10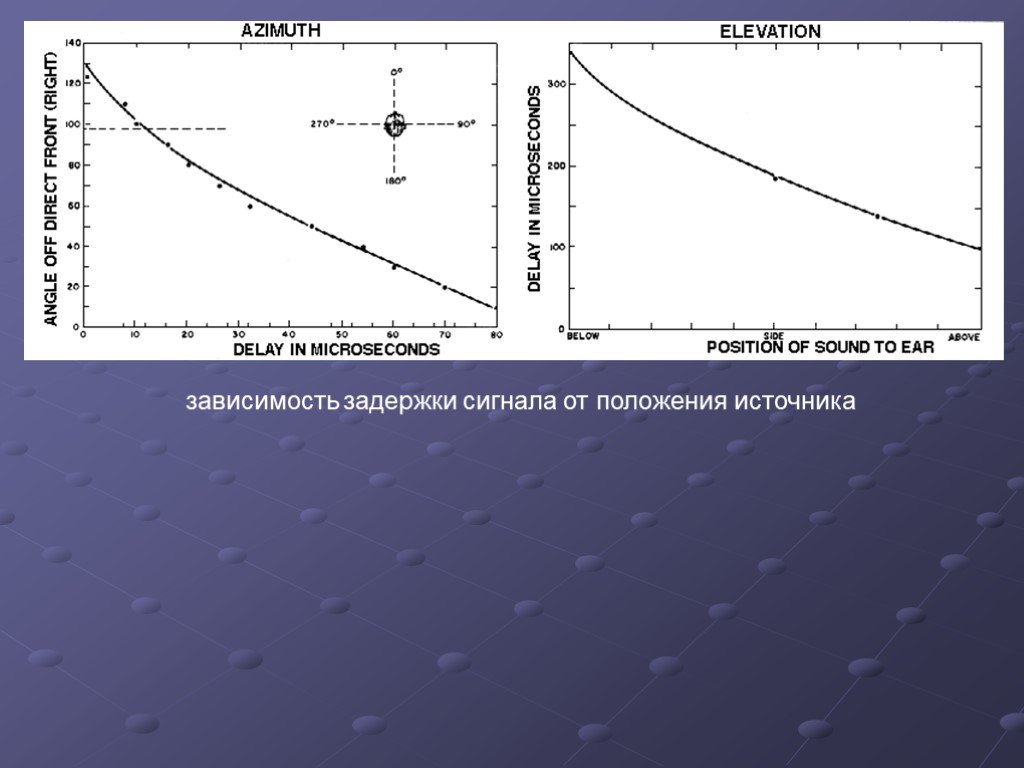 Слайд 11
Слайд 11 Слайд 12
Слайд 12 Слайд 13
Слайд 13 Слайд 14
Слайд 14 Слайд 15
Слайд 15 Слайд 16
Слайд 16 Слайд 17
Слайд 17 Слайд 18
Слайд 18 Слайд 19
Слайд 19 Слайд 20
Слайд 20 Слайд 21
Слайд 21 Слайд 22
Слайд 22 Слайд 23
Слайд 23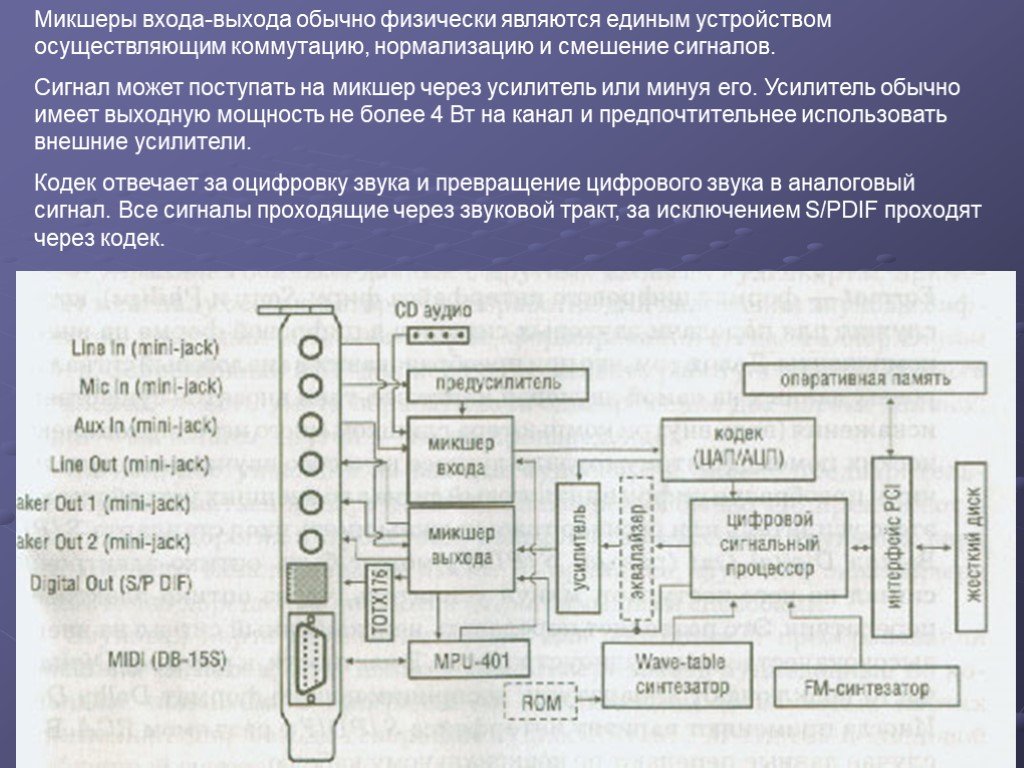 Слайд 24
Слайд 24 Слайд 25
Слайд 25 Слайд 26
Слайд 26




























